This post is the first in a series on Seq’s storage engine. It’s a technical dive meant to share some of the more interesting aspects of its design and implementation.
Seq is a log server with its own embedded storage engine for log events written (mostly) in Rust. We call this storage engine Flare. We’ve written a bit about our experiences with Rust in the past, but we’ve been wanting to dive into the design of Flare itself since we first shipped it in August of 2018.
To get a sense of what Flare is all about we’ll first introduce its broad design and then explore some of its components. We’ll do this by tracing the ingestion of an event through Seq’s HTTP API through to disk, and then later back from disk via a query, and finally deleting the event entirely. This post is a long and tangential tour of the design and implementation of the database to provide context for deeper dives into specific components in future posts.
Other posts in this series
Contents
- The design of Flare
- Ingesting events
- Merging write-optimized files into read-optimized files
- Querying events
- Deleting events
The design of Flare
Flare is a conceptually small database. It’s fully abstracted from the underlying OS and doesn’t attempt to do any of its own threading, even though it’s designed for concurrent access. That makes it nicely portable (it can actually run entirely in WebAssembly) and embedded in other programming languages. In Seq, we embed Flare in .NET.
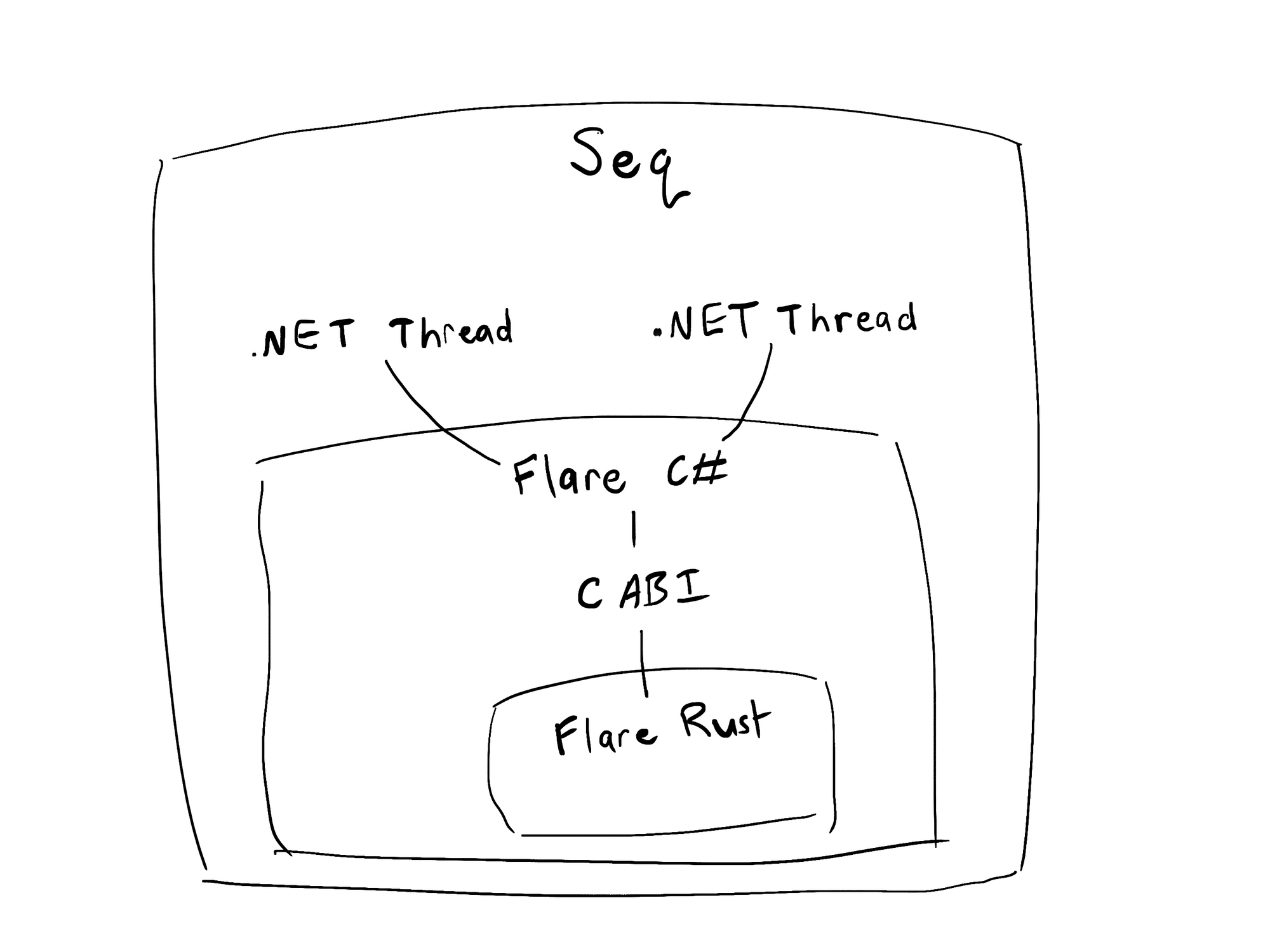
Choosing trade-offs
As a database, Flare only has three things to worry about:
- Storing data on disk.
- Removing data from disk.
- Fetching data from disk.
Doing those things efficiently though, while also guaranteeing ACID properties (that is, atomicity, consistency, isolation, and durability), is actually very tricky! Even lightweight general-purpose embedded databases like SQLite are complex. Flare isn’t a general-purpose database though. To maintain performance and reliability within a manageable level of complexity, Flare takes advantage of some properties of log events in its design. Log events are:
- immutable.
- schema-less.
- about 1Kb in size on average.
- written with recent timestamps.
- deleted with old timestamps.
We alluded to performance and reliability as constraints on Flare's design above, but there are others we have too:
- Understandability. We're a small team with a lot of code to maintain. We need Flare to be understandable so we can quickly reconstitute the mental stack needed to work on it.
- Supportability. Flare is deployed in environments we have no control over. We need it to be as robust as possible and give us plenty of insight into how it's running.
These properties together have lead to a design where data files can be initially appended to, but are eventually aged into an immutable format. Deletes are filtered copies into new data files.
There are some trade-offs in Flare’s design:
- the database is tolerant of some historical and future writes, but regular random writes (such as applications logging using really skewed system clocks) have poor performance characteristics.
- keys have to be slowly incrementing, so the only key that makes any sense is a timestamp.
- there are no random deletes, and retention isn’t really a mechanism for quickly reclaiming disk space.
Transactions and state
Flare is transactional. It has three different kinds of transactions each with different capabilities for interacting with the state of the database:
- Read transactions. These give access to the data files and can iterate through their log events. There can be any number of read transactions and they don’t block any other transactions.
- Write transactions. These allow data files to be created, log events to be appended to them, and for those data files to be marked as read-only. There can only be one write transaction at a time.
- Maintenance transactions. These allow immutable data files to be created and reshaped. They’re used for long-running background tasks. There can only be one maintenance transaction at a time.
Flare uses a series of locks and MVCC (multi-version concurrency control) internally to manage its transactions. MVCC is a technique for allowing concurrent access to state by making changes to that state generational. State is accessed by grabbing the current generation, and is updated by creating a new generation that includes any changes. In Rust, we can model MVCC nicely using the standard Arc<T> atomic reference counted smart pointer.
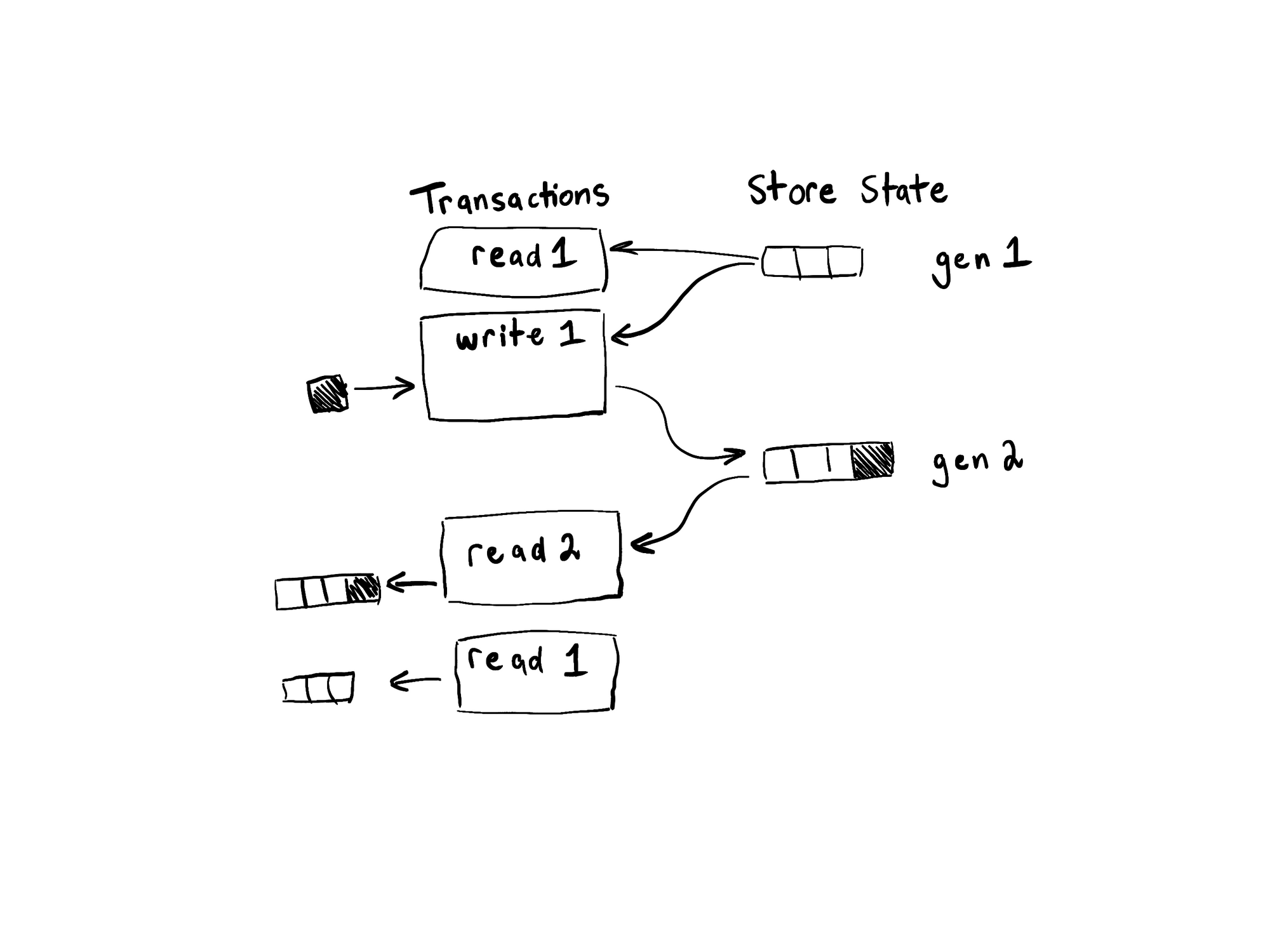
The locks live at the heart of Flare together with the in-memory state of the database. This in-memory state is a MVCC generational set of all the database’s files and metadata. When a transaction is started it receives a snapshot of the current generation’s set of files to work with. Since transactions only see the generation that was current when they were started they don’t observe any changes made by other transactions.
As an example, consider the following chain of events:
- A read transaction,
read1, is started. It’s based on the current generation1. - A write transaction,
write1, is started. It’s based on the current generation1. - The write transaction appends some data.
- The write transaction is committed. This moves the current generation to
2to include the newly appended data. - A read transaction,
read2, is started. It’s based on the current generation2. - Data is read from
read2. It sees the data appended bywrite1. - Data is read from
read1. It doesn’t see the data appended bywrite1.
What’s next?
Flare is an embedded, transactional collection of data files that’s designed with embedding and streamlined support in mind. With that bit of context, let’s dive a little deeper by following a log event through the engine from ingestion through to querying and deletion.
Ingesting events
Let’s say we have this log event:
{
"@t": "2020-07-29T07:10:16.1729056Z",
"@mt": "Health check {Method} {TargetUrl} {Outcome} with status code {StatusCode} in {Elapsed:0.000} ms",
"HealthCheckTitle": "Health Endpoints",
"Method": "GET",
"TargetUrl": "myapp/health",
"Outcome": "succeeded",
"Elapsed": 124.02390000000001,
"StatusCode": 200,
"ContentType": "application/json; charset=utf-8",
"ContentLength": 84,
"ProbeId": "aOiAcXYe0Znd",
"Data": {
"version": "1.5.314",
"environment": "Production",
"checks": {
"database": {
"isOk": true
}
}
},
"ProbedUrl": "myapp/health?__probe=aOiAcXYe0Znd",
"@r": [
"124.024"
]
}The log event first arrives as JSON at Seq’s HTTP ingestion endpoint, which is based on ASP.NET. From there it’s deserialized into a regular .NET object and appended to a write queue for persistence. The queue is flushed by serializing its waiting log events into a normalized JSON format and sending in a batch to Flare to write to disk, then adding them to Seq’s RAM cache. From here everything is Rust.
When a write needs to be performed in Flare, it is done under the write lock as part of a write transaction. The write lock ensures there’s only ever a single write transaction active at once. A write transaction is capable of creating and appending to the files used to durably persist log events. These files are called ingest buffers (if you have a Seq instance handy, you can find ingest buffers by looking for .tick files in your Stream folder).
Ingest buffers
Each ingest buffer is an unordered, append-only list of log events whose timestamps all fall within a fixed 5 minute range. We call these 5 minute ranges ticks (which is where the .tick extension comes from).
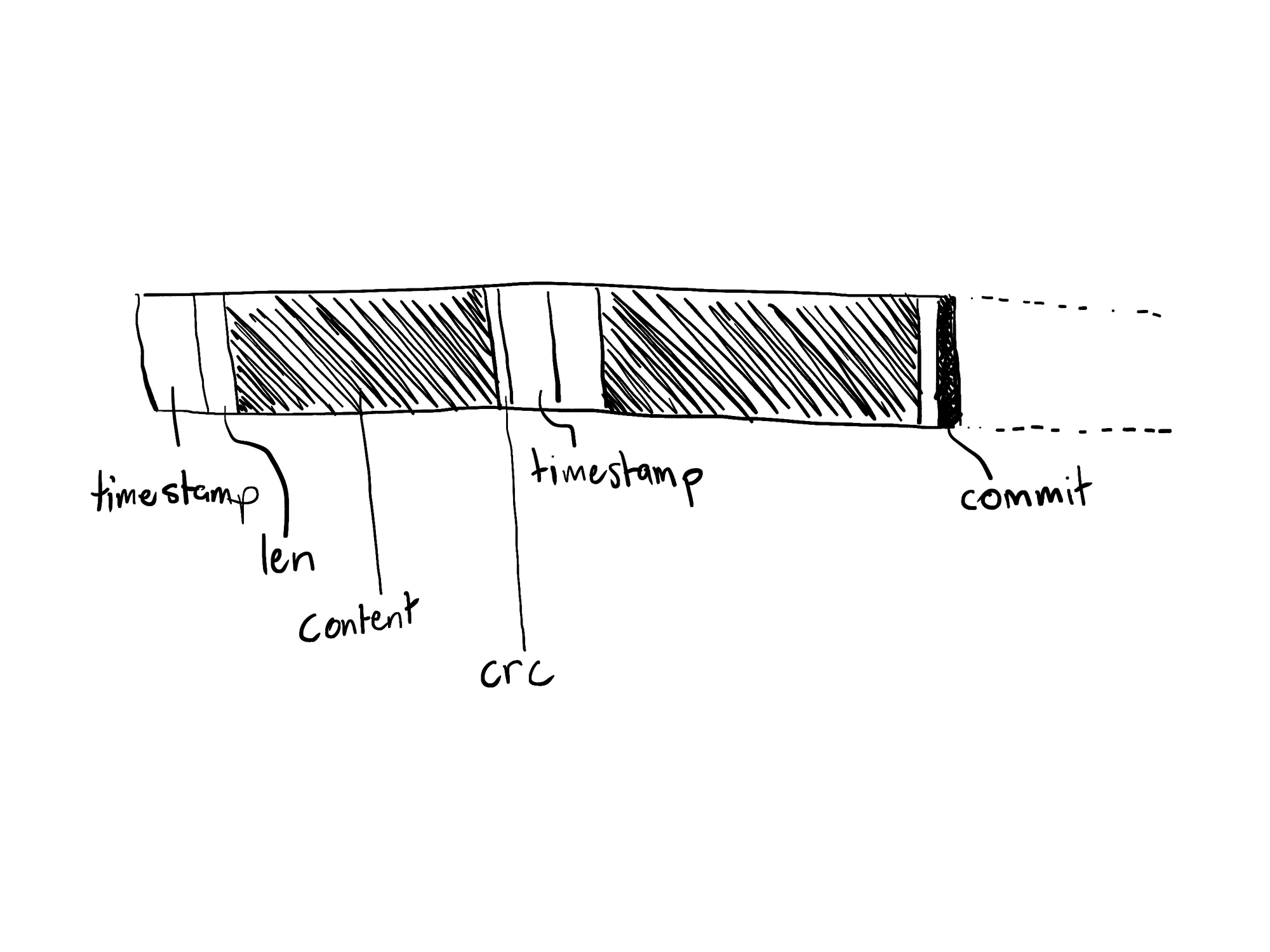
Log events encoded as JSON are written to an ingest buffer compressed using the snappy algorithm. These compressed bytes are staged in an in-memory buffer before reaching the underlying file. We ended up writing an implementation of the snappy framing protocol that uses a 1Kib frame size to keep its space requirements bounded (everything in Flare is designed to work in bounded space, so that it leaves plenty of RAM for the cache). Flare uses headers and trailers to separate encoded log events in all its data files, including ingest buffers, rather than a line or null delimited protocol. The header for each log event contains its timestamp and the length of the encoded payload. The trailer contains a CRC hash of the payload.
The in-memory buffer may be flushed to disk on-demand. Log events that are flushed to disk aren’t visible to new reads until they’ve been committed though. This ensures that, within the span of time covered by a .tick file, batched writes either succeed or fail atomically, and never leave the file in a corrupted, partially-committed, or ambiguous state. Committing an ingest buffer is done by fully flushing the in-memory buffer to disk, then writing a single 0xCC commit byte to the data file and flushing again. The double-flush makes sure all written memory pages have actually been persisted to real storage, which isn’t necessarily guaranteed by a single flush on all filesystems. If the writes made to the data file don’t cross a page boundary then the double flush is avoided as an optimization in favor of a single flush after writing the commit byte.
Once the batch pulled from the write queue containing our event has been written and committed, the database advances its in-memory state to a new generation containing the file offset to the new commit byte. Then the write transaction is completed (usually to be immediately followed by a new one). Other transactions started from this point will be able to see the new batch of events.
What’s next?
So that’s how a log event sent to Seq’s HTTP API is persisted by Flare on disk. Before we look at how the event can be queried back from disk let’s give it some time to age into a different format. Ingest buffers are optimized for writes but are very slow to read in order, because they need to be sorted first.
Merging write-optimized files into read-optimized files
Once an ingest buffer has been left unmodified for about an hour (we call this period the ingest window) it becomes a candidate for merging along with other ingest buffers into a new file format that’s optimized for reads. Flare expects a cache to sit in front of its ingest buffers that covers the ingest window (plus a bit more). Seq has a RAM cache in C# for this. Since most log streams are far bigger than the RAM available to a single machine though, Flare needs to be able to serve historical reads from disk too. This is where coalescing comes in.
Background operations like merging are performed under the maintenance lock by a maintenance transaction. Like a write transaction, there can only be one maintenance transaction active at a time, but maintenance transactions don’t block read or write transactions. Maintenance can be long-running, so these transactions are allowed to checkpoint their work and update their generation. That way data files can be cleaned up while maintenance is still running.
Stable spans
The merging process rewrites the events from a contiguous set of ingest buffers into an immutable, sorted stable span (if you have a Seq instance handy, you can find stable spans by looking for .span files in your Stream folder). There are some heuristics used to find a good size for the resulting spans, based on the number, size, and age of the candidate ingest buffers.
Stable spans use a page-based format on disk. The first few bytes of every page in the span contain an offset to the start of the next event. That makes it possible to find the first timestamp that falls within a range in the memory-mapped stable span by binary searching its pages and looking at the timestamp of the next event.
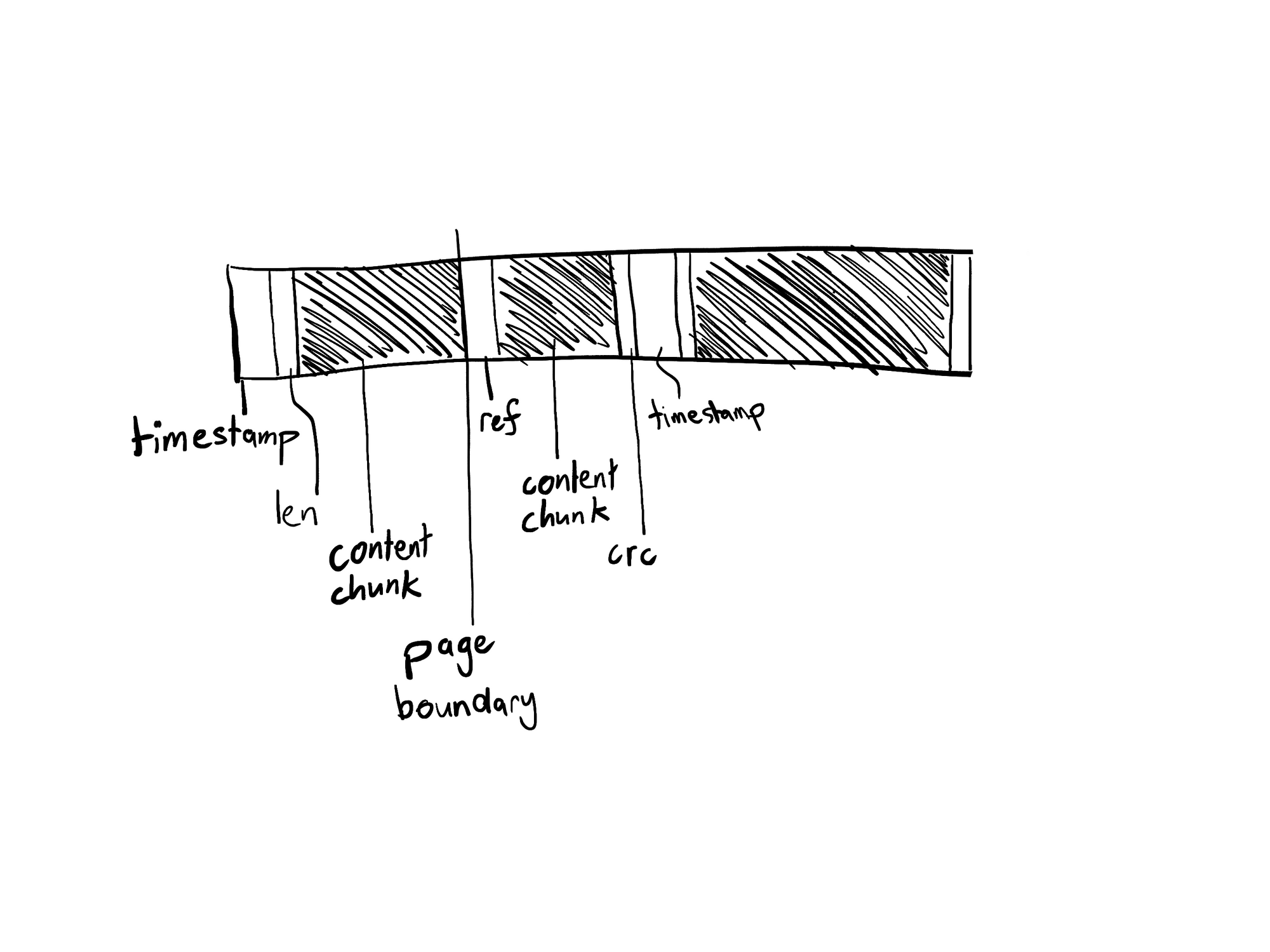
Each stable span stores a set of page-based indexes as bitmaps (these are .index files that live alongside the .span files). How these bitmaps are constructed isn’t important to Flare, today Seq creates these indexes automatically based on the filters in signals. Flare uses these indexes to issue madvise calls on Linux and PrefetchVirtualMemory calls on Windows to control how pages will be pulled from disk.
What’s next?
Stable spans are sorted and page-based on disk, so they can be scanned through very efficiently by avoiding pulling pages from disk that don’t need to be read. Now that our event has been coalesced into a format that’s optimized for reading from disk, we can follow a query from the Seq UI that will read it from disk.
Querying events
Say we run the following query in Seq:
select StatusCode from stream where Method = 'GET' and Elapsed > 100with a signal selected that has the following filter:
Environment = 'Production'and a time range covering the day of 2020-07-29 (that’s the timestamp of our example event from before).
The query first reaches Seq’s C# query engine, which deals with aggregate operators like count and group by and also takes care of executing the query against the RAM cache. Once a query needs data from disk, it’s transpiled into a Flare query.
Flare’s query API is new in Seq 2020.1, and uses a language-first design that will slowly replace the chatty low-level ones currently used for indexing and retention. We’ve been calling Flare’s language NQL (for Native Query Language). It’s not a user-facing language yet, but is still pretty fleshed out with its own support for features like JSON-like object literals, lambdas, and branching. NQL is a subset of the familiar Seq query language, and the above Seq query is actually identical in NQL.
Query compilation
The first step in retrieving events from Flare is to compile the query text. This happens in several phases, with the output of one phase being fed directly as input into the next.
Parsing
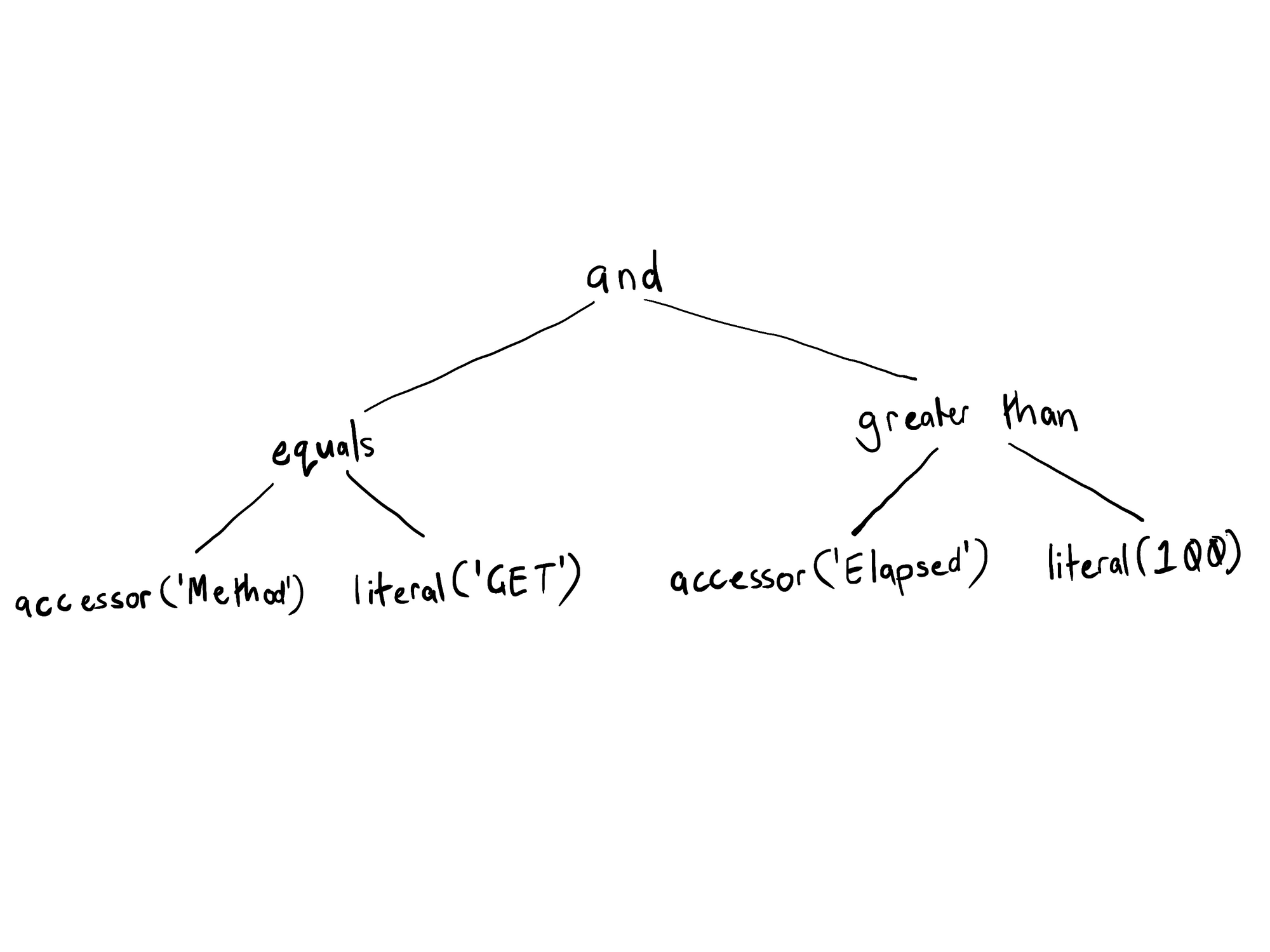
Flare queries consist of a projection and a predicate. The projection is the part of the query that projects data in the log events into columns. The predicate is the part of the query that filters the documents to be projected. In the example query, the projection is StatusCode and the predicate is Method = 'GET' and Elapsed > 100. The first phase of query evaluation is the parser, where the query text is converted into an AST (abstract syntax tree).
The AST for the query predicate includes a root node with the and operator with nodes for the equality operator over the Method accessor and GET string literal on one side, and the greater-than operator over the Elapsed accessor and 100 number literal on the other.
The parser doesn’t focus on good error messages yet, because the queries Seq provides it should never fail to parse.
Planning
Once the query text has been parsed, the next phase is planning. The goals of this phase are to analyse and optimize the AST into a more efficient form for execution. Some examples of optimizations performed during planning include unrolling any and all iterators and extracting fragments of the query that can be evaluated on raw JSON bytes without deserializing them first.
The planning phase also examines accessors in the query predicate and projection to figure out how much of the target log event needs to be deserialized. Avoiding needing to deserialize and parse numbers, allocate for maps, and unescape large strings is a great boost to query throughput. In our example query, only the StatusCode, Method, Elapsed, and Environment properties are needed. These are later fed to the deserializer.
Linking
Flare uses an interpreter to evaluate queries. The AST is walked and converted into a recursive set of virtual function calls. This approach gives reasonable performance for the fairly small ASTs produced by Flare queries, and has the benefit of being nicely portable to environments that don’t support code generation. We have thought about a potential JIT for NQL in the future though, maybe based on something like cranelift. A proper JIT would solve some inherent limitations with the performance of recursive function calls, but would introduce a suite of new challenges to solve.
Query evaluation
At this point the query is ready to evaluate against documents pulled from disk.
Reading from disk with indexes
When a read is performed in Flare, it’s done using a read transaction. There can be any number of read transactions open at a time, and they don’t block write or maintenance transactions in any way.
Under a read transaction, the database will give a reference to all files with events that fall within the query time range of 2020-07-29. We’ll just consider the case where all of these files are stable spans (reading from ingest buffers is not the happy path for Flare queries).
Our example query uses a single signal (Environment = 'Production'), so it has a single page-based bitmap index associated with it. Before any stable span is opened the relevant indexes are consulted and if they don’t contain any hits the entire stable span file can be ignored.
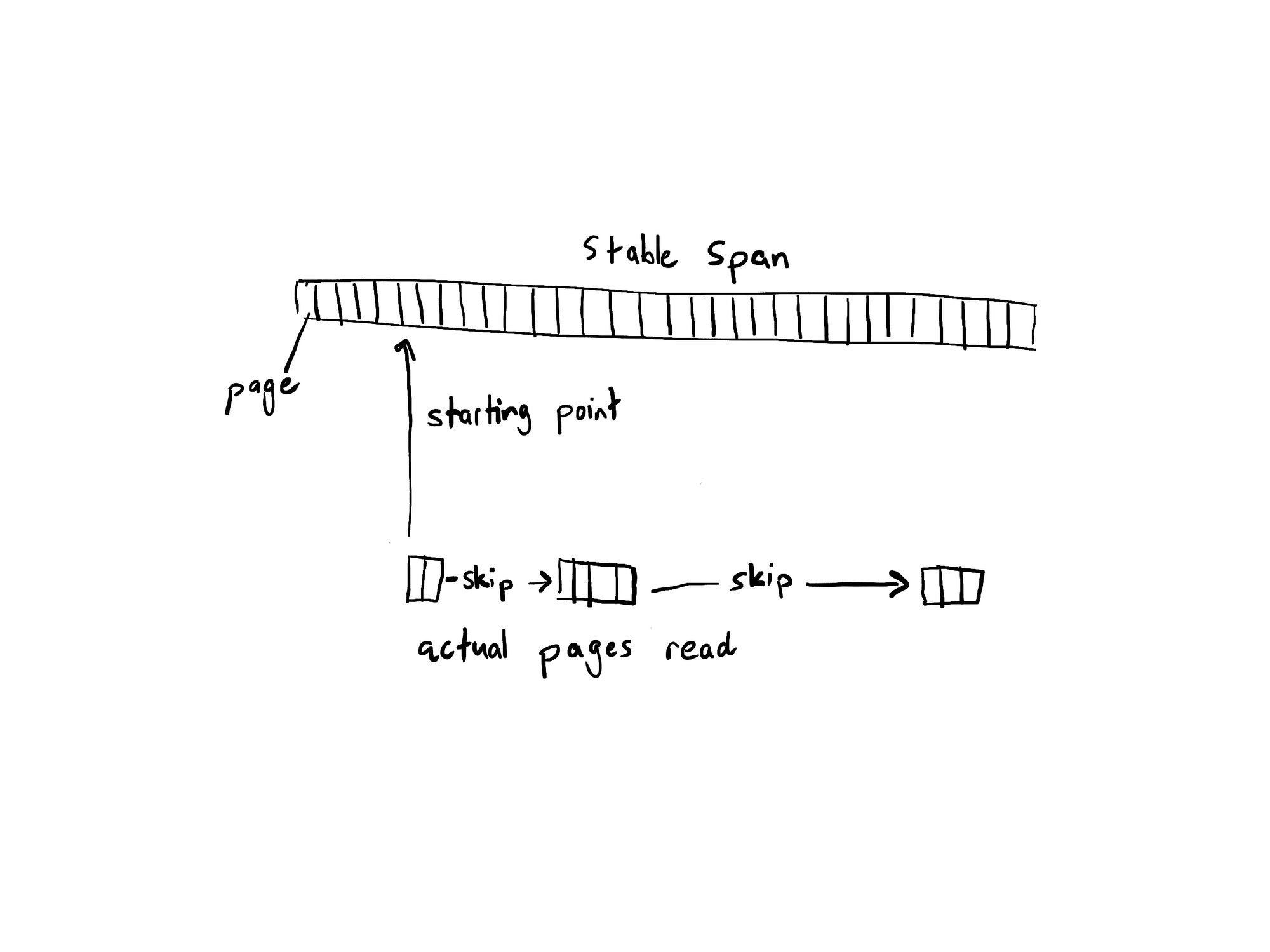
Stable spans are opened by memory mapping them. The starting point for reading is found by guessing a page in the file with an event timestamp that’s close to the query range and binary searching to the first event that has a timestamp in the range. This is possible because the stable span format we described earlier always stores the offset to the start of the next event at the start of each page.
Event payloads are read by stepping through the events in the file from the starting point. The index is consulted after each event to find the next marked page. This can avoid pulling pages from disk if the index is sparse and lots of pages can be skipped. Indexes are effective for low-cardinality properties with only a handful of unique values, like deployment environments or application names.
Pre-filtering raw event bytes
Before the event payloads that were read from a stable span are deserialized, they’re first loosely filtered by the query to see if they have any hope of matching the full predicate. This is done by extracting fragments of the query predicate into regexes during planning that are matched against raw document byte content. These regexes can produce false positives (match documents that don’t actually match the predicate) but can’t produce false negatives (fail to match a document that would match the predicate). In our example predicate:
Method = 'GET' and Elapsed > 100they query will extract the following very simple regex fragment:
\"GET\"so that only documents that contain the text GET somewhere will be inspected further.
This approach is effective for queries over high-cardinality properties with a lot of possible unique values, like correlation ids and other UUIDs.
Deserializing events
For events that are pulled from disk and pass pre-filtering, the next step is to deserialize them from JSON. Only the properties that are needed by the query are fully deserialized, which means performing string unescaping and precise number parsing.
Flare has its own JSON deserializer that is designed to efficiently read portions of pre-validated maps that may contain large escaped strings. It’s vectorized using AVX2 intrinsics (we decided to target AVX2 for a start after finding widespread support for it in common cloud environments) and borrows ideas from simd-json for identifying structural JSON characters in a 32-byte block using just a few instructions. Unlike simd-json, Flare’s deserializer doesn’t attempt to vectorize parsing further than that, because it needs to offer a complete fallback implementation. The end result is still a very fast deserializer that performs better than any alternatives we’ve tried for Flare’s specific workload.
Projecting rows
In the final phase of query evaluation, the deserialized document is fed to the running query. It outputs a row as an array containing the projected columns which are then returned to Seq. Our example query with its projection of StatusCode would produce a rowset like:
[
[200],
[200],
[404],
[302],
[404],
[200]
]The same evaluation process is repeated for each event until the read transaction reaches the end of the time range.
What’s next?
We’ve just explored a bit of Flare’s query engine for NQL, its language for SQL-like rowset queries over JSON data. Log events (preferable) stored in stable spans can be queried using NQL until they’re no longer useful and are cleaned up by retention.
Deleting events
Over time, log data becomes less relevant and can be flushed out of Seq to save disk space. This process is called retention.
Flare performs retention under the maintenance lock using a maintenance transaction, just like the merging process we saw earlier. Retention is done lazily by Flare. During retention, Flare never attempts to shrink or rewrite files in-place, only to delete them entirely or replace them. Never rewriting portions of files that have already been written helps keep the database easy to reason about. But it means retention isn’t guaranteed to actually reclaim any disk space. The size of the database on disk is reduced by replacing a set of larger files with a single smaller one.
Data files that are removed by retention aren’t deleted immediately, because they may still be used by read transactions tracking older generations. Instead, the actual data file deletion is added to a shared work queue, tagged with the last generation that can access the data files. When transactions complete they check this queue, and if they’re the last for a given generation then they perform the work queued for it.
What’s next?
That’s been a whirlwind tour of Flare, the embedded database we’ve built as Seq’s log event store. We’ve got a lot more planned for Flare in the future, and there’s a lot more we want to dig through in more detail in follow-up posts, like the NQL language, sparse deserializer, and how the MVCC in-memory state is wired up.
Watch this space!