Deserializing JSON really fast
This post is part of a series digging into the internals of Flare, Seq’s embedded event store written in Rust. In this post we’re going to look at how Flare deserializes JSON documents stored on disk using a very fast bespoke, sparse, vectorized deserializer called squirrel-json. You can find the source for squirrel-json on GitHub.
squirrel-json is written specifically for Flare, and makes heavy tradeoffs in order to serve Flare's use case as effectively as possible. It's not a general-purpose JSON deserializer like serde_json or simd_json. The upside of those tradeoffs are that it improves our query throughput by about 20% compared to simd_json:
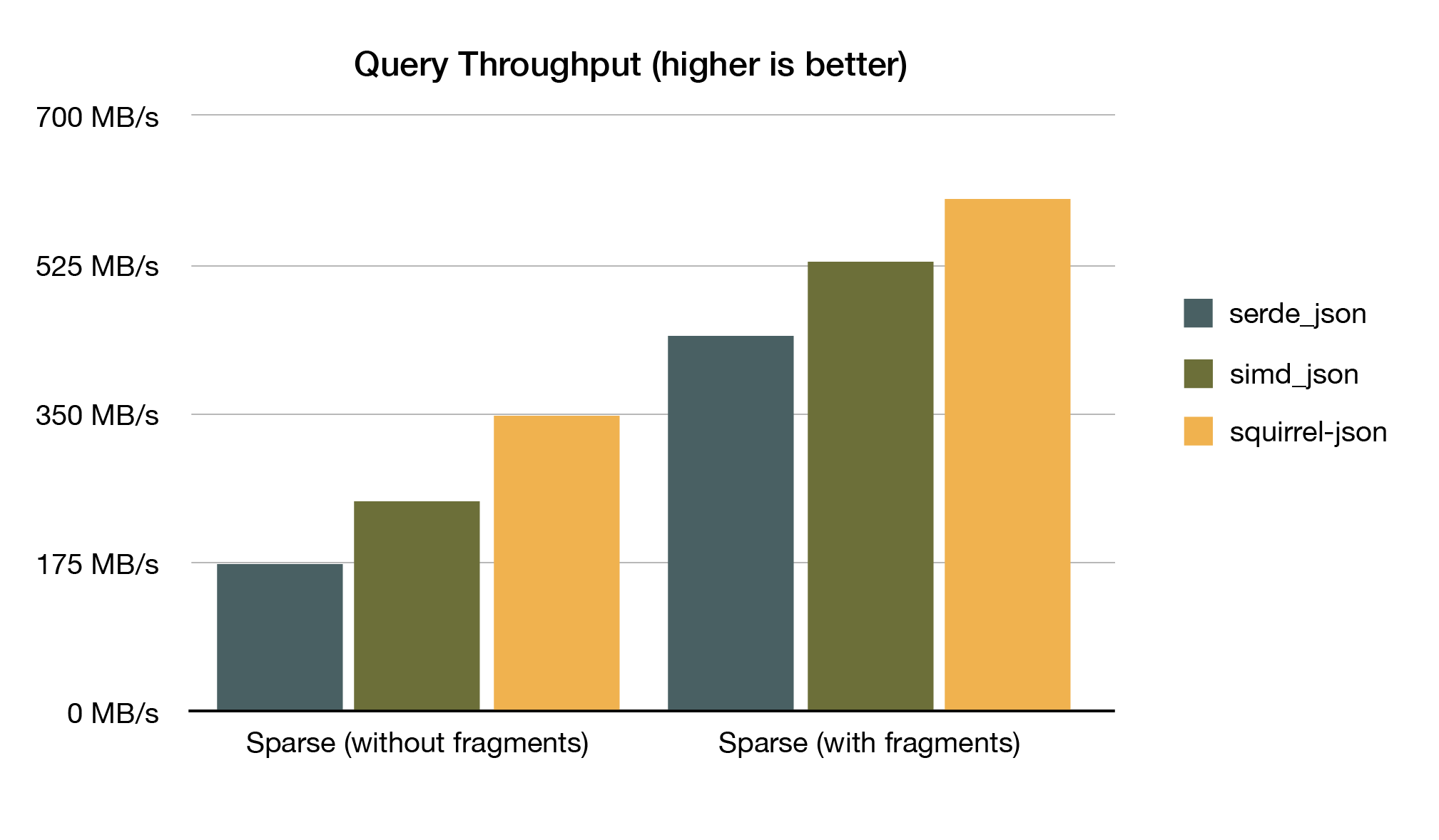
See the Results section at the end of the post for more details on how we drew those bars.
Contents
- First, an example
- What does Flare need from a deserializer?
- How do we make something fast?
- What doesn’t Flare need from a deserializer?
- How it all works
- Guaranteeing freedom from undefined behavior
- Results
- Summing up
First, an example
To get an idea of what squirrel-json does, lets say we have a line-delimited JSON file we want to scan through and sum up all the Elapsed properties we find. This is conceptually similar to how Flare executes queries. Using squirrel-json, this scanning can be done very efficiently, only paying the cost of fully deserializing the Elapsed property for each document:
use std::{
error::Error,
fs,
io::{
BufRead,
BufReader,
},
};
use squirrel_json::{
Document,
de,
};
use rust_decimal::Decimal;
fn main() -> Result<(), Box<dyn Error>> {
// open our line-delimited file
let mut file = BufReader::new(fs::File::open("lines.json")?);
let mut buf = String::new();
// create a detached document to share the allocation needed to parse documents
let mut reuse = Some(de::DetachedDocument::default());
// some stats about what we found in the document
let mut elapsed = Decimal::default();
let mut scanned = 0;
while file.read_line(&mut buf)? > 0 {
// scan the document, attaching and reusing any allocations made parsing previous documents
let doc = Document::scan_trusted_attach(buf.as_bytes(), reuse.take().unwrap());
// all documents are a JSON map at their root
// this map isn't like the standard library's `HashMap` or
// `serde_json`'s `Map`. It's a totally flat structure
// that can skip through JSON properties at the same depth,
// skipping over the properties that belong to nested arrays or maps
let map = doc.as_map();
// look for an `Elapsed` property and parse it as a decimal
// this won't parse any other numbers or unescape any strings
let v = map
.entries()
.find_map(|(k, v)| match (k, v) {
// this isn't exactly a JSON number, but is good enough for us
(k, de::Kind::Num(v)) if k.as_raw() == "Elapsed" => v.parse::<Decimal>().ok(),
_ => None,
});
elapsed += v.unwrap_or_default();
scanned += 1;
reuse = Some(doc.detach());
buf.clear();
}
// see what we found!
println!("scanned: {}", scanned);
println!("total elapsed: {}", elapsed);
Ok(())
}
The above example demonstrates a few features that squirrel-json has to optimize for its query use case. We'll dig into their motivation and implementation in more detail below.
What does Flare need from a deserializer?
I mentioned squirrel-json is a deserializer written specifically for Flare. Why would Flare need a specially crafted deserializer? It needs a deserializer that can convert UTF-8 documents into concrete values quickly while using as little of its own resources as possible. Deserialization is on the hot path in queries that need to process every document that falls within the query’s time bounds.
It also needs to guarantee some runtime bounds regardless of the input, because the data it processes may be corrupted externally. That includes freedom from undefined behavior (such as attempting to access memory out-of-bounds) and completing processing within bounded space and time. These are table stakes for any code that accepts outside input, though, so we’re not going to focus on them for a start.
How do we make something fast?
So in order to serve our use case, squirrel-json needs to be stable and fast. How do you make a deserializer fast? For that matter how to do you make anything fast? The answer I find most useful is do less work. It doesn't say much on its face, but it helps you spot opportunities to avoid doing work that isn't actually necessary.
What doesn’t Flare need from a deserializer?
If the way we can make squirrel-json fast is to do less work then the real question to ask isn’t what Flare does need from a deserializer, but what it doesn't need. Flare doesn't need its deserializer to:
- Check that documents are valid JSON because that was already done when they were ingested. That means we don’t need to consider error handling while the deserializer is progressing because there shouldn’t be any. On it’s own this statement should start ringing alarm bells, but remember we still guarantee freedom from undefined behavior whatever the input! We just don’t need to guarantee any particular deserialization results when the input is malformed.
- Handle internal white space because documents are stored minified. That means we can guarantee the next character after a JSON key will be a
:and the next character after that will be the start of the value. - Consider properties in the document that aren’t used by the query. That means not parsing numbers or converting string escape sequences (unescaping) strings unless the query needs to look at them.
How it all works
The input to the deserializer is a byte array containing UTF-8-encoded JSON, which the deserializer scans through and converts into a linked list of offsets to the positions of keys, values, maps, and arrays in the input. The deserializer is built around a set of callback functions that are invoked whenever a particular kind of character is encountered. These functions transform some internal state that keeps track of string, number, object, and array boundaries. We call these callbacks interest functions because they’re invoked on interesting JSON characters. The object of the parser is to find all the interesting characters in the JSON input and invoke the appropriate callback for them.
There are two implementations for finding interesting characters that operate in a loop:
- A portable byte-by-byte version that checks each byte for an interesting character.
- An AVX2 vectorized version that operates on 32-byte blocks and can skip through to find interesting characters in just a few instructions.
The internal state and callback functions are shared between the portable and vectorized implementations, so the parser can freely switch between the two when scanning through a document. This design decision limits the use of intrinsics in the AVX2 implementation to just identifying and scanning to interesting characters, but lets the code for constructing the linked list be shared. Sharing more code between the two implementations makes it easy to keep them in sync and fewer opportunities to introduce bugs.
The deserializer proceeds in a few steps:
- Use Rust's
strmodule to check that the input is valid UTF-8. - Scan through the input byte-by-byte up to the first 32-byte aligned boundary.
- Scan through the input in 32-byte blocks until there are less than 32 bytes left.
- Scan through any remaining input byte-by-byte.
The output of the deserializer is a Document, which is a linked list of offsets for the keys, values, maps, and arrays in the document. These offsets can then be traversed to construct a sparse tree of JSON values, including just the properties that are needed for the query.
Say we have the following input (we're showing it as formatted instead of minified here so it's easier to read):
{
"timestamp": "2020-03-12T17:08:37.6065924Z",
"message": "Redirecting to continue intent checkout,rhl0KPfqiBmCX",
"intent": "checkout,rhl0KPfqiBmCX",
"actionId": "18871b88-eec6-4b1b-b386-58ced474cf1a",
"actionName": "Website.ShopController.Checkout",
"requestId": "0HLU5OL5TQ32T:00000001",
"requestPath": "/shop/checkout",
"spanId": "|8869e95f-4e39591237d13f93.",
"traceId": "8869e95f-4e39591237d13f93",
"parentId": "",
"connectionId": "0HLU5OL5TQ32T",
"application": "MyApp.Web",
"imageVersion": "1.0.677",
"site": "Production"
}
It can be deserialized to a Document using its scan_trusted method:
let doc = Document::scan_trusted(input);
When run through the deserializer, it will produce a Document as output:
Document {
offsets: [
{value: "timestamp", escaped: false, position: Key, offset: 0, next: Some(2)},
{value: "2020-03-12T17:08:37.6065924Z", escaped: false, position: Value, offset: 1, next: Some(3)},
{value: "message", escaped: false, position: Key, offset: 2, next: Some(4)},
{value: "Redirecting to continue intent checkout,rhl0KPfqiBmCX", escaped: false, position: Value, offset: 3, next: Some(5)},
{value: "intent", escaped: false, position: Key, offset: 4, next: Some(6)},
{value: "checkout,rhl0KPfqiBmCX", escaped: false, position: Value, offset: 5, next: Some(7)},
{value: "actionId", escaped: false, position: Key, offset: 6, next: Some(8)},
{value: "18871b88-eec6-4b1b-b386-58ced474cf1a", escaped: false, position: Value, offset: 7, next: Some(9)},
{value: "actionName", escaped: false, position: Key, offset: 8, next: Some(10)},
{value: "Website.ShopController.Checkout", escaped: false, position: Value, offset: 9, next: Some(11)},
{value: "requestId", escaped: false, position: Key, offset: 10, next: Some(12)},
{value: "0HLU5OL5TQ32T:00000001", escaped: false, position: Value, offset: 11, next: Some(13)},
{value: "requestPath", escaped: false, position: Key, offset: 12, next: Some(14)},
{value: "/shop/checkout", escaped: false, position: Value, offset: 13, next: Some(15)},
{value: "spanId", escaped: false, position: Key, offset: 14, next: Some(16)},
{value: "|8869e95f-4e39591237d13f93.", escaped: false, position: Value, offset: 15, next: Some(17)},
{value: "traceId", escaped: false, position: Key, offset: 16, next: Some(18)},
{value: "8869e95f-4e39591237d13f93", escaped: false, position: Value, offset: 17, next: Some(19)},
{value: "parentId", escaped: false, position: Key, offset: 18, next: Some(20)},
{value: "", escaped: false, position: Value, offset: 19, next: Some(21)},
{value: "connectionId", escaped: false, position: Key, offset: 20, next: Some(22)},
{value: "0HLU5OL5TQ32T", escaped: false, position: Value, offset: 21, next: Some(23)},
{value: "application", escaped: false, position: Key, offset: 22, next: Some(24)},
{value: "MyApp.Web", escaped: false, position: Value, offset: 23, next: Some(25)},
{value: "imageVersion", escaped: false, position: Key, offset: 24, next: Some(26)},
{value: "1.0.677", escaped: false, position: Value, offset: 25, next: Some(27)},
{value: "site", escaped: false, position: Key, offset: 26, next: None},
{value: "Production", escaped: false, position: Value, offset: 27, next: None}
]
}
Notice the next field at the end of each key and value. For keys, these point to the next key at the same depth (so that nested objects can be easily skipped when scanning). For values, these point to the next value at the same depth. The role of next is more obvious when the input contains nested objects and arrays.
The Document can then be iterated over like a normal map. As an example, we could find the connectionId property, and then unescape it without touching other properties:
let (k, v) = doc.as_map().entries().find(|(k, v)| k.as_raw() == "@connectionId");
let unescaped: String = v.as_str().unwrap().to_unescaped().into_owned();
The key for Document is that it only parses structure, it doesn't attempt to unescape strings or parse numbers except for properties that are explicitly asked for. Not unescaping strings is especially important for the common case of having very large stack traces with embedded newlines in documents.
Scanning JSON
The AVX2 implementation only operates on 32-byte aligned blocks, because in AVX2 aligned loads are faster than unaligned ones. It turns out that in general it’s worth scanning up to (but usually fewer than) 31 bytes byte-by-byte before vectorizing. Flare itself is optimized around an average document size of 1KiB so this still leaves plenty of input to feed to the vectorized implementation. The byte-by-byte implementation is fairly straightforward, so let's take a look at the AVX2 one instead.
The AVX2 implementation works by producing a set of indexes for each 32-byte block that match the positions of interesting characters in the input. There's an index for quotes and escapes, and an index for all characters of interest. The quote index is a subset of the interest index.
Say we have the input {"a":"An escaped: string\n"}, the indexes produced for it will look like this:
input: {"a":"An escaped: string\n"}
index_quote: 0101010000000000000000001010
index_interest: 1101110000000000100000001011
The AVX2 implementation produces both sets of indexes, but only examines one at a time. When it's inside a string it uses index_quote, otherwise it uses index_interest. The goal of splitting the indexes is to be able to very quickly scan through very large strings that may contain structured characters like : and , internally.
The quote index matches any " or \ character, and is produced in a straightforward fashion using AVX2 instructions to identify bytes that are equal to ", then any equal to \, and then computing a bitwise or to combine the results. It looks something like this:
let index_quote = {
let match_quote = _mm256_cmpeq_epi8(block, _mm256_set1_epi8(b'"' as i8));
let index_quote = _mm256_movemask_epi8(match_quote);
let match_escape = _mm256_cmpeq_epi8(block, _mm256_set1_epi8(b'\\' as i8));
let index_escape = _mm256_movemask_epi8(match_escape);
index_quote | index_escape
};
The interest index matches any :, {, }, [, ], ,, ", or \ character. This set is quite a bit larger than the one matched by the quote index so it uses a different strategy to match them. Requiring two vectorized instructions per character to match is expensive. The solution is borrowed from simd_json and uses shuffles with specially crafted index tables to identify all the characters we're interested in using just a few instructions. There's a nice description of the process in the original simdjson paper. It looks something like this:
// use a lookup table to classify characters in the input into groups
// this is the same approach used by `simd-json`, which makes it possible
// to identify a large number of characters in a 32byte buffer using only a few
// instructions
let index_interest = {
// the characters we want to match need to be put into groups
// where each group corresponds to a set bit in our byte
// that means in 8 bytes we have 8 possible groups
// each group must contain a complete set of chars that match
// the hi and lo nibbles, otherwise there could be false positives
const C: i8 = 0b0000_0001; // `:`
const B: i8 = 0b0000_0010; // `{` | `}` | `[` | `]`
const N: i8 = 0b0000_0100; // `,`
const E: i8 = 0b0000_1000; // `\`
const Q: i8 = 0b0001_0000; // `"`
const U: i8 = 0b0000_0000; // no match
// once we have groups of characters to classify, each group
// is set for the indexes below where a character in that group
// has a hi or lo nibble
// for example, the character `:` is in group `C` and has the nibbles `0x3a`
// so the byte in the lo table at index `a` (10 and 26) are set to `C` and
// the byte in the hi table at index `3` (3 and 19) are set to `C`
let shuffle_lo = {
_mm256_setr_epi8(
// 0 1 2 3 4 5 6 7 8 9 a b c d e f
U,U,Q,U,U,U,U,U,U,U,C,B,N|E,B,U,U,
// 0 1 2 3 4 5 6 7 8 9 a b c d e f
U,U,Q,U,U,U,U,U,U,U,C,B,N|E,B,U,U,
)
};
let shuffle_hi = {
_mm256_setr_epi8(
// 0 1 2 3 4 5 6 7 8 9 a b c d e f
U,U,N|Q,C,U,B|E,U,B,U,U,U,U,U,U,U,U,
// 0 1 2 3 4 5 6 7 8 9 a b c d e f
U,U,N|Q,C,U,B|E,U,B,U,U,U,U,U,U,U,U,
)
};
let lo = block;
let match_interest_lo = _mm256_shuffle_epi8(shuffle_lo, lo);
let hi = _mm256_and_si256(_mm256_srli_epi32(block, 4), _mm256_set1_epi8(0x7f));
let match_interest_hi = _mm256_shuffle_epi8(shuffle_hi, hi);
// combining the lo and hi indexes ensures only characters with matching lo and hi
// nibbles in the appropriate group are kept
let interest_lo_hi = _mm256_and_si256(match_interest_lo, match_interest_hi);
let match_interest = _mm256_cmpeq_epi8(interest_lo_hi, _mm256_set1_epi8(0));
let index_interest = _mm256_movemask_epi8(match_interest);
// in the end we identify characters that _aren't_ in the set we're interested in
// so all we need to do is invert the index and we're done
!index_interest
};
The core of the AVX2 implementation shifts over zeroes in the active index to quickly find interesting characters:
// since `index_interest` is a superset of `index_quote` we know we're done
// when it's empty
while index_interest != 0 {
// the active index is `index_quote` when we're inside a string
// and `index_interest` in all other cases
let block_offset = indexes[active_index].trailing_zeros();
let shift = (!0i64 << (block_offset + 1)) as i32;
index_interest &= shift;
index_quote &= shift;
..
}
The way the AVX2 implementation works with interesting characters once they've been identified is the same as the byte-by-byte implementation.
How is squirrel-json different to simd_json?
The AVX2 implementation in squirrel-json borrows ideas from simd_json but differs from it in a few ways:
simd_jsonrolls UTF-8 validation into its vectorized parsing phase, so it doesn't need to pass over the input twice.squirrel-jsonuses its identified interesting characters as indexes to shift over, whilesimd_jsonuses them as masks to apply other intrinsics to before passing to a more traditional deserializer. That meanssimd_jsondoes more constant-time work per block thansquirrel-json, which is always bound to the number of interesting characters it needs to process.simd_jsonuses its input as a scratch buffer for unescaping, so it needs it to be given as a&mut Vec<u8>instead of a&[u8].
Guaranteeing freedom from undefined behavior
In Flare we have a general pattern of using environment variables to produce checked builds. These builds are like debug++, they do things like replace all explicit unchecked operations with their safe checked variants and enable model-based testing.
Checked builds are automatically used when running unit tests. They’re also used when running fuzz tests. squirrel-json is fuzz tested using AFL to check that:
- All string slices are always valid UTF-8.
- All offsets are within the bounds of the original document.
- There are no panics.
- There are no hangs.
- If
serde_jsonparses the input thatsquirrel-jsonwill too, and that the results are the same.
Fuzz testing is a really powerful technique for finding bugs in software. It’s truly unforgiving and will thrash your software, but finding and fixing bugs through fuzz testing is very satisfying. Some of the JSON inputs AFL generated for squirrel-json include:
{"V":-0}
{"a":4} 2
{"a":"\\\\\\u\\\\"}
{:42e10}
{"a"],42}
Those are all examples of inputs that originally caused panics, undefined behaviour, or invalid results and needed to be fixed up.
Results
How efficiently can squirrel-json scan through JSON documents? To find out, we'll dig into how it impacts query time compared with full JSON deserializers in the Rust ecosystem.
These benchmarks are going to compare the impact of various JSON parsers on Flare's query throughput. This section is careful not to try compare JSON parsers in general-purpose workloads, because we're not trying to suggest squirrel-json is faster than, say, simd_json in general, only in Flare's very specific workload of deserializing documents for evaluating its query predicates and projecting columns. squirrel-json is only faster because it doesn't do things that a general-purpose JSON parser needs to. With those caveats out of the way let's look at some results!
The test dataset
When working on Flare, we have a flaretl tool that supports benchmarking queries against in instance of the store to help understand the performance characteristics of the query engine. flaretl actually ships with Seq itself so you can use it on your own instances.
The command we're running will look like:
❯ ./flaretl.exe bench --cases ./cases_de.txt --percentile 90 .
It will run each query 10 times and output stats around the 90th percentile.
The build of flaretl.exe we're using is produced in the following way:
- On Windows.
- In release mode with
opt-level = 3. - Using
target-cpu = nativeto target my i9 9900K CPU (this is necessary forsimd_jsonto compile, since it's entire design is based around intrinsics). - Using full link-time-optimization with
lto = "fat"andcodegen-units = 1. - Overriding the system allocator with
mimalloc.
The store we're going to benchmark is on Windows, has just over 1.3 million events, and is just shy of 500MB on disk:
events (count): 1369670
value data (bytes): 490895586
It's made up of 14 span files with indexes:
❯ ls .
Length Name
------ ----
100 cases_de.txt
3508224 flaretl_flarejson.exe
3493888 flaretl_serde_json.exe
3521024 flaretl_simd_json.exe
3117 stream.08d6eece8023b000_08d6f447ace44400.9a8fff8a49d64c9184787b3732365bc5.index
31785352 stream.08d6eece8023b000_08d6f447ace44400.9beb558f021b47dc81d7e7041ba151fa.span
14121139 stream.08d6f44b2af61a00_08d6f9c88898e200.0767076b8b55465d811fbcd4baca4dda.span
1497 stream.08d6f44b2af61a00_08d6f9c88898e200.2ffb5e30a29746e7ae63b52146a2c9c1.index
36918284 stream.08d6f9c93b694000_08d6ff48b17d2200.06115a75e6e44d528b68876e340453c5.span
3585 stream.08d6f9c93b694000_08d6ff48b17d2200.a9bf13027e9445c38104f5689f4029db.index
1809 stream.08d6ff49644d8000_08d704c98d31c000.0efd43a35bcd444494d965a847de622e.index
17523333 stream.08d6ff49644d8000_08d704c98d31c000.ae4fb3c2924e4ae4b512a99cf6b67d59.span
519 stream.08d704cba5a2da00_08d704cf23b4b000.af6dd28858d14c2c895a4b3340e1bd8a.span
156 stream.08d704cba5a2da00_08d704cf23b4b000.d7a07921a6084346b379338c9b632190.index
36664756 stream.08d704cfd6850e00_08d70a490345a200.4c4f117bdb0c4cc8844285e97a0e96a9.span
3561 stream.08d704cfd6850e00_08d70a490345a200.6b6f47fb3fc1442799f6e1d0cbc64aaf.index
3582 stream.08d70a49b6160000_08d70fc9defa4000.138cf86194e2471bb2f97d738595d977.index
36893436 stream.08d70a49b6160000_08d70fc9defa4000.f77d4497028a4e38ab9c1f410acf2422.span
2742 stream.08d70fca91ca9e00_08d713f6904c0c00.5d582a49f8294ec48ab3ef1ceadd2aba.index
27701080 stream.08d70fca91ca9e00_08d713f6904c0c00.e4eae52cc6cc4da9b2babee556530383.span
741 stream.08d713f6904c0c00_08d714d07e3e9c00.7e91af908ba2486eb6e65a6fc50f05fb.index
5839755 stream.08d713f6904c0c00_08d714d07e3e9c00.fb588f07a44840c49fefbf36f421e4d0.span
525 stream.08d714d07e3e9c00_08d7154a07de8000.038e686a906a4aedae6244b0d0532f87.index
3479347 stream.08d714d07e3e9c00_08d7154a07de8000.7de051980ab04f0cbfb369062e360dfd.span
3603 stream.08d7154c204f9a00_08d71aca30c2c000.7055dadb921948d1ba6925d6d54cabb8.index
37095919 stream.08d7154c204f9a00_08d71aca30c2c000.88c27d8d129b4856afbefa90064129f9.span
37006571 stream.08d71accfc043800_08d72049a6d6a200.4faf0ba56f03436aaeae78234469a153.span
3594 stream.08d71accfc043800_08d72049a6d6a200.d7da7da4525a4b089d1d4fcb2d03ae59.index
3570 stream.08d7204a59a70000_08d725ca828b4000.1acbbb6fda59429782618eec5d167d45.index
36765039 stream.08d7204a59a70000_08d725ca828b4000.a64acac4998d4c838f7fead021015c63.span
3432 stream.08d725cd4dccb800_08d72b49f89f2200.7f46c06ed75c4e80a7c1d97f004b7857.index
35241810 stream.08d725cd4dccb800_08d72b49f89f2200.b4ec4c721c2c4c49a0a7470d67fe9b46.span
2535 stream.08d72b4b5e3fde00_08d730ca21836200.875aaef5b6e34d90baa64746dbf650a3.index
25459195 stream.08d72b4b5e3fde00_08d730ca21836200.c5b516a69ca343e5bfed6394f8d437c4.span
30754953 stream.08d730cad453c000_08d73586b680d200.1e02d63e03b24ce1804c372f92870291.span
3021 stream.08d730cad453c000_08d73586b680d200.ade128a709b046e49cc498e6e114f88d.index
1906 stream.08d7358cffd42000_08d735abbba44800.6d1ffac2d1034c59826e146caa27133e.index
10913253 stream.08d7358cffd42000_08d735abbba44800.d31d548514254409be72a7c70ceed383.span
6161 stream.1.metadata
8 stream.flare
The query cases we're running are:
❯ cat ./cases_de.txt
select Message from stream where Elapsed > 200
select Message from stream where match(Message, '/api/customers')
The first query case needs to unescape the Message property and parse the Elapsed property. The second query case only needs to unescape the Message property, and can also take advantage of regex fragments to avoid deserializing documents at all.
serde_json
The serde framework is Rust's canonical serialization API with support for JSON in the serde_json crate. It's a great baseline to use because it already offers good performance while being straightforward, portable, and well documented. If you need to read or write JSON in Rust you're probably going to reach for serde_json first.
❯ ./flaretl_serde_json.exe bench --cases ./cases_de.txt --percentile 90 .
loading cases from "./cases_de.txt"...
analyzing store at "."
store: "."
events (count): 1369670
value data (bytes): 490895586
timestamp range: 11749819104773678396437393883023802369..11751256330103492678279385380543588014
runs: 10
percentile: p90th
running 2 case(s)...
(case 001) select Message from stream where Elapsed > 200... 2697747800 ns (+5060000/-22235100 ns)
(case 002) select Message from stream where match(Message, '/api/customers')... 1057967500 ns (+92400/-12353600 ns)
| case | p90th (+/-) | tp (events) | tp (hits) | hits | tp (data) | query |
| 001 | 2.70 s (+ 5.06 ms/- 22.24 ms) | 507708/s | 158501/s | 31% | 173.54 MB/s | select Message from stream where Elapsed > 200 |
| 002 | 1.06 s (+ 92.40 μs/- 12.35 ms) | 1294623/s | 245133/s | 18% | 442.50 MB/s | select Message from stream where match(Message, '/api/cust |
As a baseline, with serde_json the query engine evaluates 173.54 MB/s for the first case, and 442.50 MB/s for the second.
simd_json
The simd_json crate is a Rust port of the simdjson C++ library. It's a state-of-the-art vectorized JSON parser that uses SIMD intrinsics in clever ways to do a good chunk of its work in constant-time. It's a crate to reach for if you need the absolute best-in-class performance and are able to target specific CPUs.
In order to parse a simd_json::OwnedValue from the input buffer we first need to collect it into a Vec<u8>. We try to minimize the impact of this by re-using the same Vec<u8> for each document that needs to be deserialized.
❯ ./flaretl_simd_json.exe bench --cases ./cases_de.txt --percentile 90 .
loading cases from "./cases_de.txt"...
analyzing store at "."
store: "."
events (count): 1369670
value data (bytes): 490895586
timestamp range: 11749819104773678396437393883023802369..11751256330103492678279385380543588014
runs: 10
percentile: p90th
running 2 case(s)...
(case 001) select Message from stream where Elapsed > 200... 1891467400 ns (+2857400/-15454400 ns)
(case 002) select Message from stream where match(Message, '/api/customers')... 882365600 ns (+5070400/-11439300 ns)
| case | p90th (+/-) | tp (events) | tp (hits) | hits | tp (data) | query |
| 001 | 1.89 s (+ 2.86 ms/- 15.45 ms) | 724130/s | 226065/s | 31% | 247.51 MB/s | select Message from stream where Elapsed > 200 |
| 002 | 882.37 ms (+ 5.07 ms/- 11.44 ms) | 1552270/s | 293917/s | 18% | 530.57 MB/s | select Message from stream where match(Message, '/api/cust |
Replacing serde_json with simd_json improves the query engine throughput by 30% for the first case, and 16% for the second.
squirrel-json
Our internal JSON parser that takes a lot of inspiration from simd_json, but is optimized for deserialization in Flare queries.
❯ ./flaretl_flarejson.exe bench --cases ./cases_de.txt --percentile 90 .
loading cases from "./cases_de.txt"...
analyzing store at "."
store: "."
events (count): 1369670
value data (bytes): 490895586
timestamp range: 11749819104773678396437393883023802369..11751256330103492678279385380543588014
runs: 10
percentile: p90th
running 2 case(s)...
(case 001) select Message from stream where Elapsed > 200... 1338111000 ns (+20153900/-16396200 ns)
(case 002) select Message from stream where match(Message, '/api/customers')... 776833800 ns (+1171700/-4425400 ns)
| case | p90th (+/-) | tp (events) | tp (hits) | hits | tp (data) | query |
| 001 | 1.34 s (+ 20.15 ms/- 16.40 ms) | 1023584/s | 319551/s | 31% | 349.86 MB/s | select Message from stream where Elapsed > 200 |
| 002 | 776.83 ms (+ 1.17 ms/- 4.43 ms) | 1763144/s | 333846/s | 18% | 602.64 MB/s | select Message from stream where match(Message, '/api/cust |
Replacing simd_json with squirrel-json improves the query engine throughput by 29% for the first case and 11% for the second. Compared to serde_json, that 51% for the first case and 26% for the second.
Summing up
That's been a tour of the design process that lead us to implement a specialized, sparse, vectorized JSON parser for Seq's embedded event store. I hope you've found something interesting in there! There's lots of other details buried in the source code, so check it out if you're interested in exploring squirrel-json further.