At Datalust we build a log server called Seq. It's really a database, written in C#, with its own SQL-based query language, that's specifically designed for storing and querying structured log data.
For more in-depth details about how we use Rust, also see:
Adding Rust to our software stack
In the past, Seq has managed log event storage through ESENT, which is a storage technology baked into Windows. For our cross-platform Seq 5 release we’ve built a storage engine called Flare in the Rust programming language to replace our usage of ESENT.
Flare is a native library that's used within Seq, an existing C# application, through a C ABI. The Rust codebase handles the lowest-level storage concerns for Seq; ensuring bytes make it to disk, that the bytes on disk are in a consistent state and that the bytes can be read back from disk. With the addition of Flare, Seq’s software stack looks a bit like this:
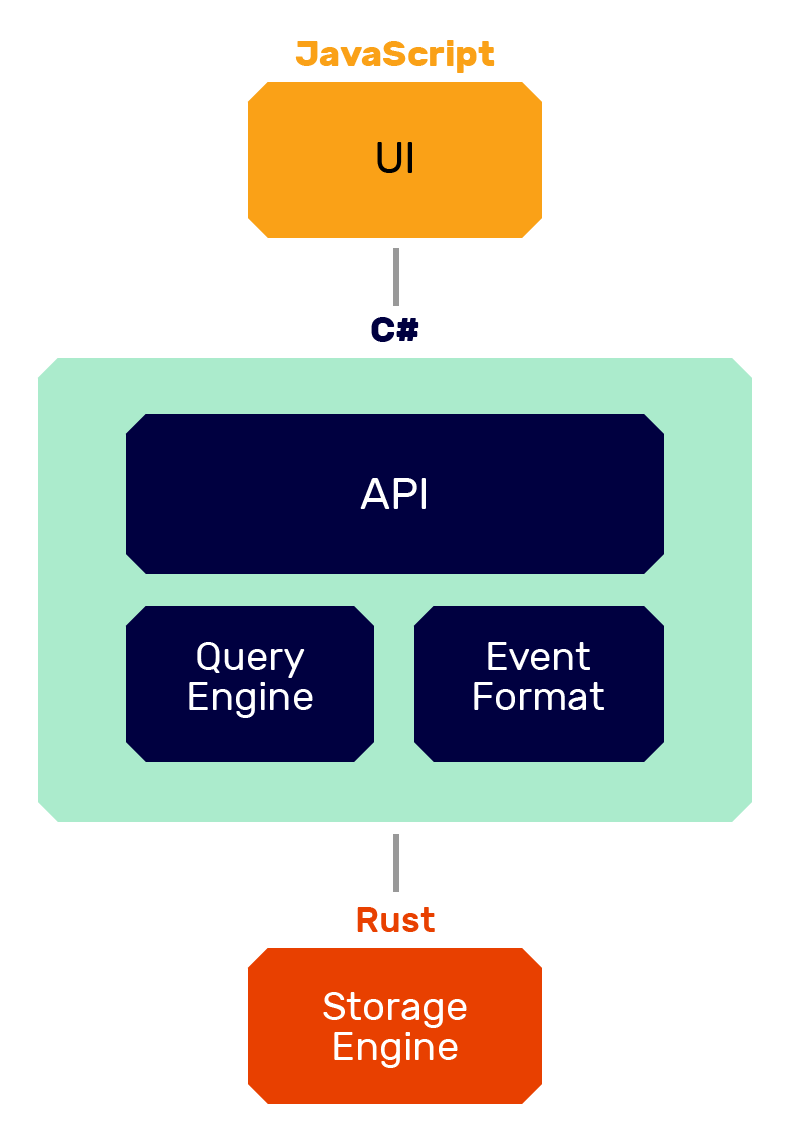
The main Seq server is a .NET Core binary, which hosts the web API and event store, including the query engine, coordination of retention policies and alerts, and the management of Flare storage extents.
Why build our own storage engine?
Log servers need to do a lot work. They need to provide timely answers to queries on enormous datasets while continuing to ingest even more data. In Flare we've built a storage engine that's tuned for ingesting and querying log events. That means efficiently performing ordered range queries on byte-array payloads that far exceed available RAM while still ingesting new events out-of-order and applying retention to old ones.
Flare takes advantage of the fact that events are immutable once written, that individual random writes and deletes are uncommon, that events arrive near the front of the stream, and that events are deleted near the back of the stream. Exploiting these properties while maintaining design simplicity has pushed us towards a very specialized storage engine design. For existing Seq users, we’re seeing around a 25% across-the-board performance improvement over the older ESENT codebase, with some specific scenarios seeing much greater gains.
There are other motivations for owning our stack all the way from the UI down to the bytes on disk. Owning our bugs means we can more effectively squash them. Owning our storage means we can push the product in whatever future direction makes sense, rather than whatever direction our underlying storage decides to take. We don't have a layer of compromise between the features we want in Seq and the way those features are handled by storage. As an example, we’ve been able to leverage Seq’s existing concept of Signals to provide a simple, but effective indexing scheme. Flare is also just the sort of thing that's really fun to build!
What we get from Rust
We like to think Rust has been around enough now that we don't need to justify it as a viable language to depend on. Having said that, it's still worth distilling some of the qualities Rust brings us that have affected the way we’ve built Flare.
Our team at Datalust is already very familiar with Rust, so we didn't need to learn the language and its ecosystem in order to get started. We already knew what we were betting on before diving into the implementation.
The Rust language and ecosystems' focus on zero-cost abstractions means we don't have to build in a high-performance subset of the language. In Rust, higher-level features like closures and iterators are as as efficient as lower-level functions and loops. The conservative approach to allocation, and minimal runtime environment also means performance characteristics are consistent, localized, and easy to reason about. First-class support for detecting and utilizing hardware intrinsics is also helpful in the cases where we want to take advantage of them.
Rust also offers a suite of fundamental tools for ensuring code is robust at runtime. The type-driven management of data ownership and concurrency, and the lack of uninitialized or null values catch a lot of potential bugs that might only be introduced after several passes of refactoring and then only observed after several years in the wild.
Writing Rust is a very methodical process. It requires deliberate design, and refactoring can sometimes feel like tedious busy-work. The reward for this upfront effort is code that's thoroughly robust, efficient, and maintainable. The way we like to think about this trade-off is that Rust doesn't minimize the time it takes to bootstrap a codebase, it minimizes the time it takes to move from one confidently working state into another. It’s a trade-off makes sense to us for a storage engine at the very heart of Seq that's responsible for the durability of your data.
What's next?
Update 19th November 2018: We've shipped Seq 5! The Flare storage engine is fully supported in production environments.
There's a long tail of burn-in work to do to make sure Flare is robust for production environments before we ship it in Seq 5. Over the longer term, we'd like to push more storage responsibilities down to the Rust end of the application, particularly the filter syntax so caching and serialization could be handled in Rust. We love C# as a very expressive and productive language for building applications though and plan to keep it as the workhorse of the Seq API.
Our preview builds of Seq 5 make Flare available as the default storage engine, so you can try it out for non-mission-critical workloads. Previews are available under the datalust/seq Docker image:
docker run \
-e ACCEPT_EULA=Y \
-v /path/to/seq/data:/data \
-p 5341:80 \
datalust/seq:latest
Our experience with Rust so far at Datalust has been a very positive one and we’re excited to share more details about how we use the language and its ecosystem in the future.