Plain-text logs are still with us! — Although newline-delimited JSON is, thankfully, an increasingly common format for log files and streams, painting a complete picture of a system still does sometimes mean slurping up unstructured output, or sifting through plain text.
Log messages like this
[2018-08-27T13:57:09.332 INF] And like this
Aug 27 13:57:10 example.datalust.co blog: And even like this
For the occasional task, grep (or my go-to ripgrep) is a satisfactory way to snoop around. If you deal with the same plain text logs a lot, want them in real-time, or need to correlate them with structured events already stored in Seq, then read on.
seqcli
Seq's new cross-platform command-line client was announced with this introductory blog post. There's a Windows MSI and .tar.gz archives for macOS and Linux on the GitHub releases page.
Running seqcli version will check that the binary can be found and executed:
> seqcli version
0.1.137
If your Seq server is at http://localhost:5341 you're ready to go. Otherwise, set the server URL and API key:
seqcli config -k connection.serverUrl -v https://seq.example.com
seqcli config -k connection.apiKey -v 12345abcde
seqcli is not yet complete, but there's a lot of useful functionality already implemented. We're on track to ship a supported version later this year alongside Seq 5.
seqcli ingest
This command gets events from STDIN or a file into Seq. By default, seqcli ingest assumes the input is plain text, and sends each line of the text as a separate event:
# Ingest one event (quotes required for PowerShell :-))
echo "Hello, world!" | seqcli ingest
Extraction patterns
Plain text logs come in all kinds of formats. Rather than simply treat each line of a text log as the "message", it's usual to want to extract things like timestamps, levels, and stack traces for separate inclusion in the final log event.
Given a log like this:
2018-08-27 14:49:52.130 +10:00 [INF] Starting up
2018-08-27 14:49:52.146 +10:00 [INF] Calculated 1 + 2 = 3
2018-08-27 14:49:52.151 +10:00 [ERR] Unhandled exception
System.DivideByZeroException: Attempted to divide by zero.
at ConsoleApp29.Program.Calculate() in C:\Development\Temp\ConsoleApp29\ConsoleApp29\Program.cs:line 35
at ConsoleApp29.Program.Main(String[] args) in C:\Development\Temp\ConsoleApp29\ConsoleApp29\Program.cs:line 17
2018-08-27 14:49:52.170 +10:00 [INF] Exiting
If each line is sent as a "message" we end up with:
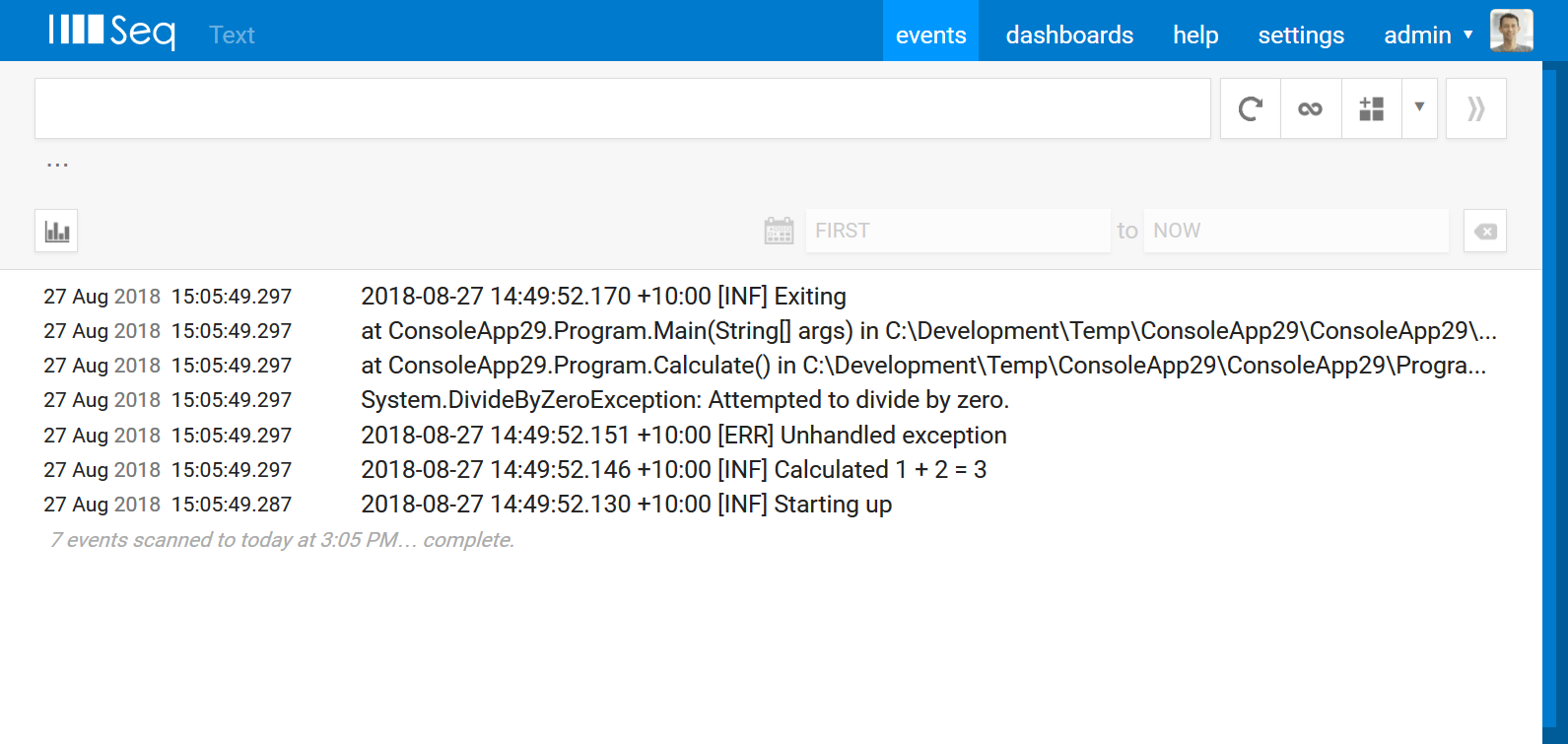
There are some obvious problems here: the timestamp gets mixed up with the message, the levels aren't detected, and the event with an exception stack trace is split line-by-line across four individual events.
What we really want is a nicely-readable stream, with all of the components of the events correctly identified, like this:
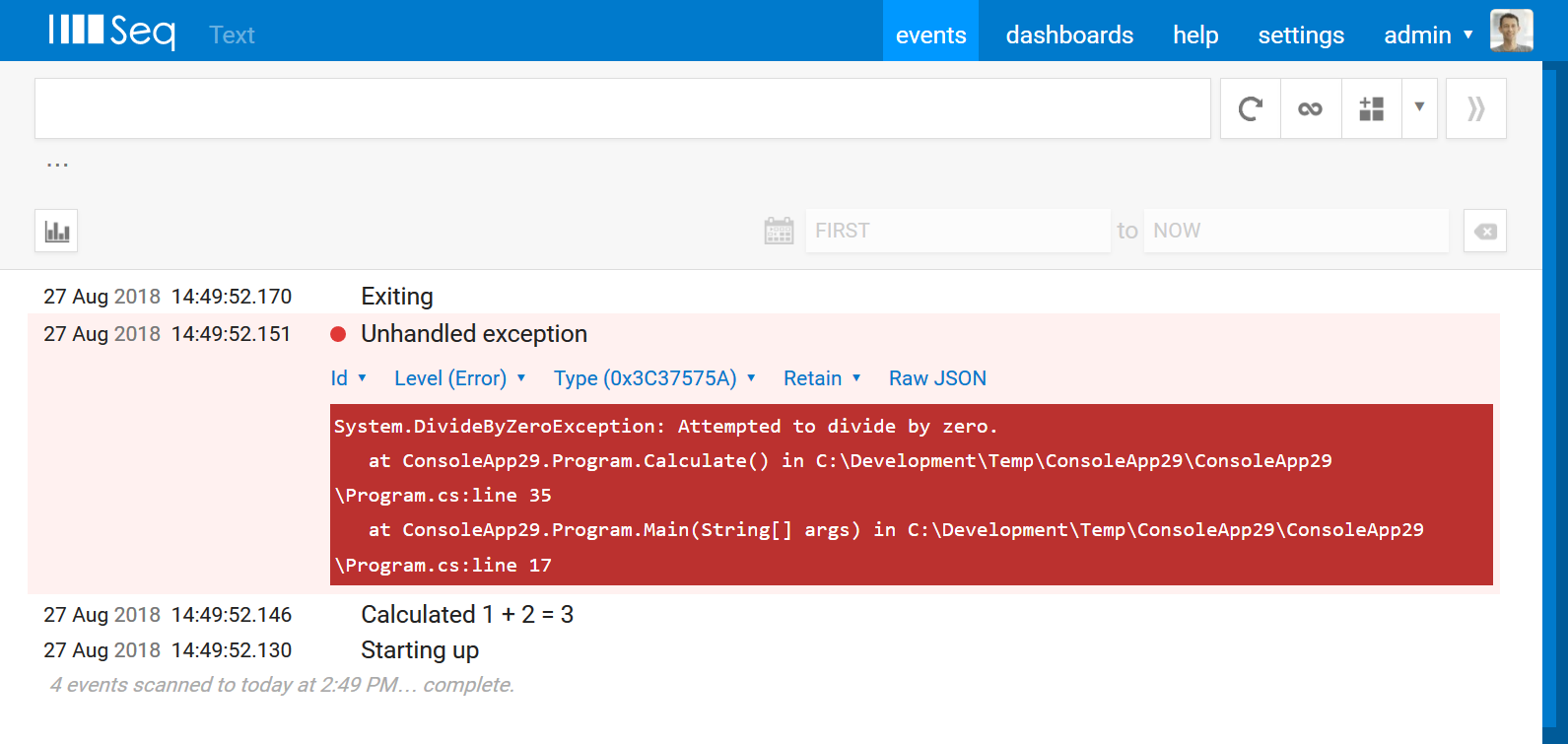
The log format happens to be the default one created by Serilog.Sinks.File.
Extraction patterns specify which parts of the text become the event's timestamp, level, message, stack trace, and so-on. Extraction patterns enable seqcli to handle many different log formats through the one ingest command.
Here's the extraction pattern used above:
{@t:timestamp} [{@l:level}] {@m:*}{:n}{@x:*}
Let's break this down.
{@t:timestamp}— this extracts the well-known timestamp component labeled@tusing thetimestampmatcher, which handles several popular timestamp formats. If the timestamp was ISO-8601, this could be specified simply as{@t}.[{@l:level}]— the@llevel component; here again the speciallevelmatcher handles translation of typical log level names into Seq's default level hierarchy. The square brackets[and]are interpreted literally, matching these precise characters (with a leading space) in the input line.{@m:*}— match everything up until the next token (*) as the message component@m.{:n}— the next token will be a newline,n. The extracted text will be discarded (there's no name to the left of the:separator).{@x:*}&mdash - finally, match everything else as the exception.
seqcli starts by matching the first token, to identify the start of a new event, and then matches as much of the pattern as possible. Missing components on the right-hand side are ignored, so not every event has to have an @x exception, for example.
Extraction patterns aren't limited to handling built-in properties like @t and @l. Specifying a non-@-prefixed property name on the left of a token, like {ThreadId:num}, will attach additional properties to the log event.
Any built-in properties that are left out will be filled with reasonable defaults.
The extraction pattern is passed to seqcli on the command-line with -x:
seqcli ingest -i log.txt \
-x "{@t:timestamp} [{@l:level}] {@m:*}{:n}{@x:*}"
How do extraction patterns work?
Behind the scenes, extraction patterns are used to construct Superpower text parsers that can be applied to the log lines.
Why base this on a parser framework and not regular expressions? The eventual goal is to be able to parse a wide - really wide - variety of formats. Regular expressions are limited to handling formats without nesting (recursion), which would rule out some more interesting use cases. If a log line is not valid JSON, but includes an island of JSON, then a more powerful parser is required to extract this correctly.
Tailing log files
seqcli accepts events on STDIN, so you can pipe the output of a process straight into it, as we saw with the first "hello, world!" example.
Tailing a log file as it is written turns out to also be a fairly tough feature to get perfectly correct, especially in a cross-platform tool. Instead of attempting it, seqcli takes on a little of the "Unix philosophy" and assumes you'll use your system's tailing feature for this.
On Linux, that's tail, so tailing /var/log/syslog is implemented as:
tail -c 0 -F /var/log/syslog |
seqcli ingest -x "{@t:syslogdt} {host} {ident:*}: {@m:*}{:n}":
This little snippet serves as a nice example of how format-specific properties, here host and ident, can be grabbed.
Deadlines and multi-line events
Applications typically write logs to their output - stream or file - a line at a time. This poses a problem for multi-line events: when ingesting the event, how do we know whether we've seen the whole event, or if there are lines yet to come?
seqcli addresses this using a 10 ms deadline: once an event is identified (by matching the first token in an extraction pattern), the event won't be sent to Seq until either another event is identified, or 10 ms elapses.
Lines that arrive late will be treated as "invalid" data. This results in an error and the process exiting by default; this can be overridden by passing --invalid-data=ignore on the command-line.
Future work
The main gap you'll notice when using seqcli ingest for plain text today is the sparse documentation concerning which matchers are supported. Rounding out the available matchers, and documenting them properly, is the top priority for the first major release. In the meantime, please jump onto the issue tracker or Seq Gitter channel and reach out if you need any help.
Happy logging!