A journal entry from the Seq Engineering Team
Back in 2018 we wrote a new storage engine for Seq, optimized for the data types and access patterns that form the largest part of Seq's workload. Although the existing server was written in C#, we used the Rust programming language for the new storage engine because of Rust's safety guarantees, performance, and precise memory management. Since then we've been working in a hybrid codebase with layers in each language.
In 2020, we pushed the filtering and projection steps of query evaluation down into Rust, leaving us with the architecture Seq uses today:
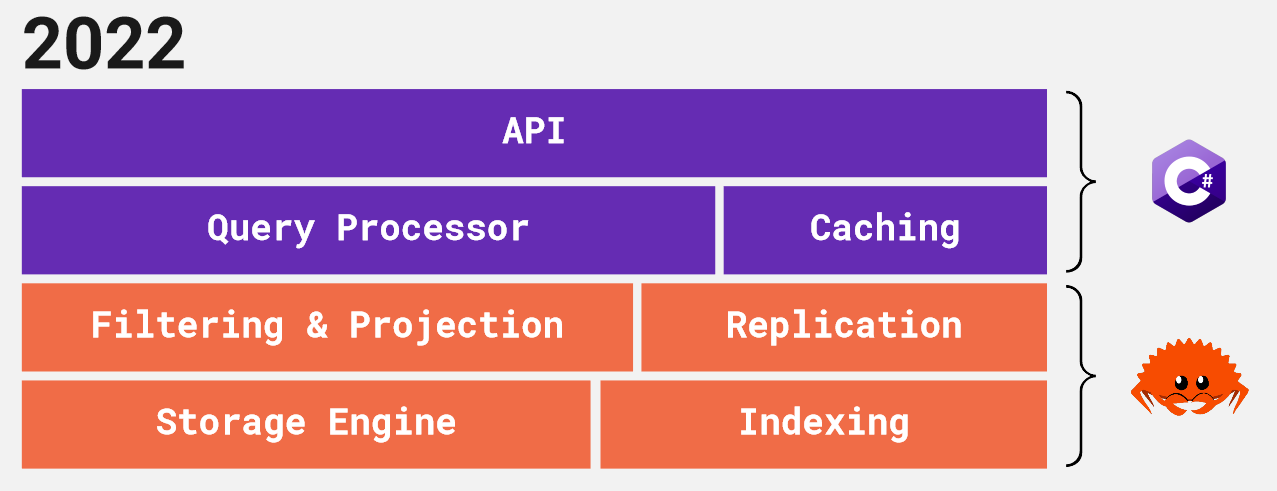
Now we're ready to take the leap: the next version of Seq will move all remaining query processing across to the native side of the codebase:
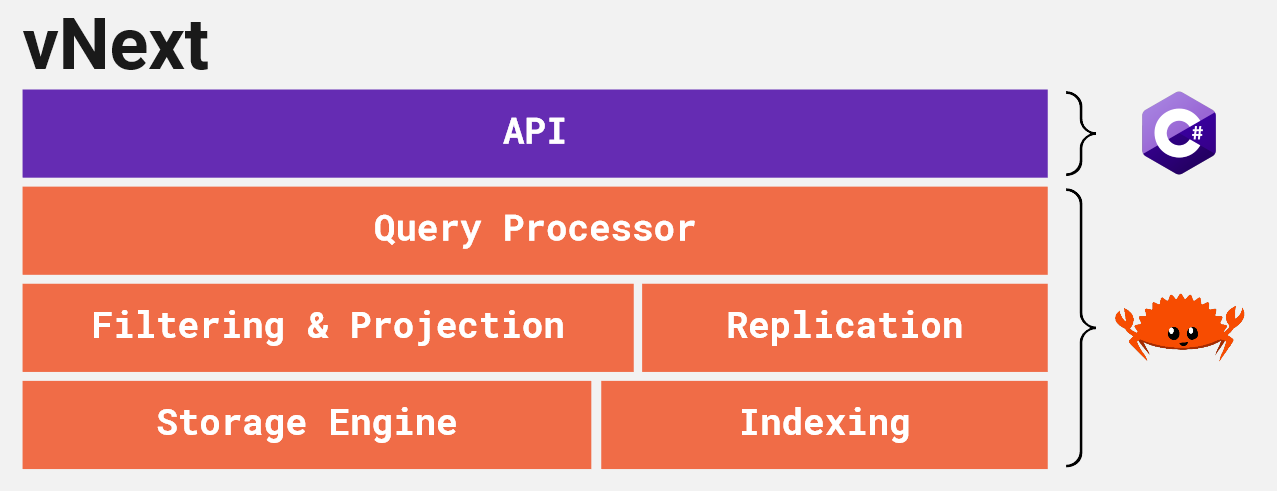
There are two reasons we're putting effort into this, and neither is that we're unhappy with C# - it's a fabulously productive and high-performing language, which we'll continue to use extensively in Seq's upper layers.
First, we're edging closer to a scale-out Seq, and want to use dataflow as the model for scheduling queries over multiple nodes (and cores), instead of the top-down query execution model we use now. For this to work, we'll need to integrate query execution very tightly with both transaction management and replication, and these are already part of our Rust codebase.
Second, by moving the last pieces of query evaluation into unmanaged code, we can keep all memory-intensive operations - including caching - away from the .NET heap. This will help us squeeze more performance and lower latency out of the same hardware.
Although we've been hard at work for several months, we haven't shared many details, so here we go! This post sets the scene, and as the release unfolds we'll loop back periodically to describe each of the main components.
It's worth pointing out, before we dig in too far, that you don't need to know any of these details in order to use Seq vNext: these are internal, behind-the-scenes changes. We hope you'll enjoy reading along and learning a little more about how Seq works.
Parsing, planning, execution
The big focus in Seq vNext is query processing. "Queries" here encompass all Seq log searches, analytic (SQL-style) queries, and dashboarding. Whether you're issuing a search in Events, rendering a dashboard, or constructing a more complex analytic query, Seq will map this to its full internal query syntax, and hand this off to the query processor for execution.
The query processor used in Seq 2022 is written in C#, and has a top-down structure that procedurally executes a range of query types. While this architecture is easy to follow, it's very hard to inject cross-cutting behavior, like parallelism over the time-partitioned spans in which Seq stores event data. Because of this, parallelism is only applied to a few specific query types in Seq 2022, leaving more performance on the table.
The new query processor breaks this into multiple steps, with the main ones shown below:
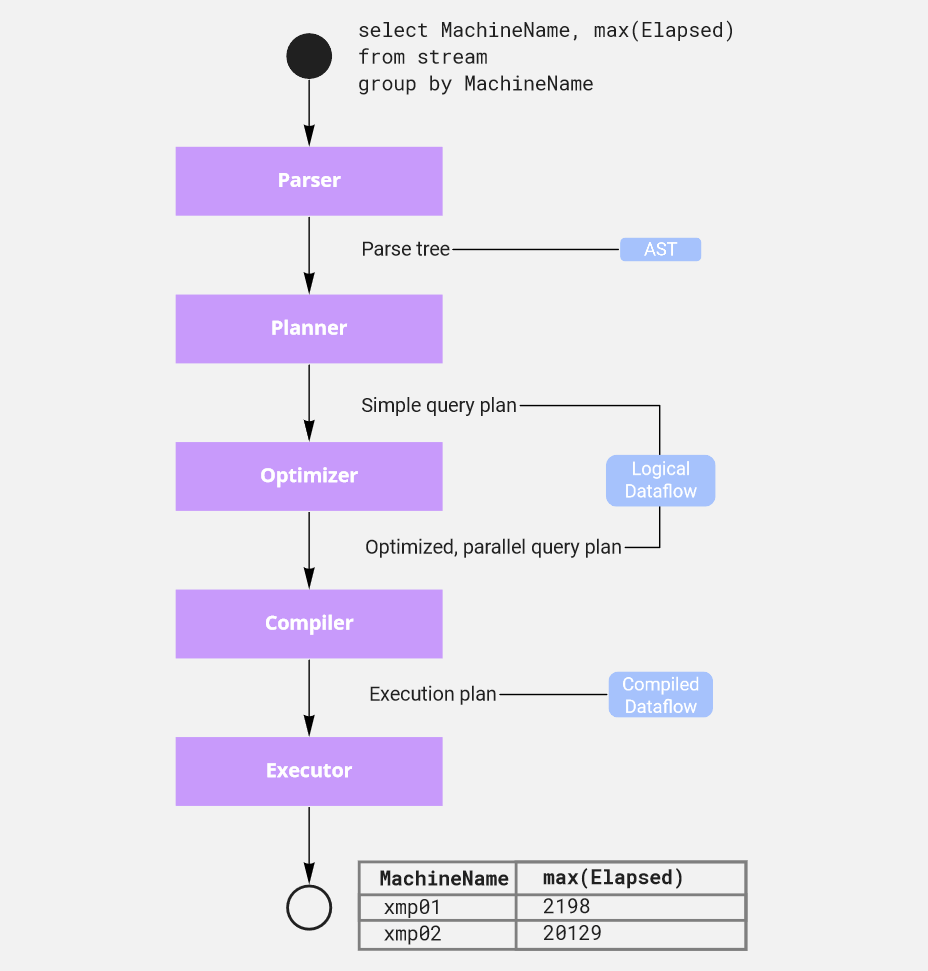
The query parser is typical, producing an abstract syntax tree (AST) from the query text. The AST itself is actually a little bit tricky: we use the same data structure to model syntactic, intermediate, and executable expressions, relying on Rust generics to keep these cleanly separated.
The following stages - planning, optimization, compilation, and execution - take the simple declarative instructions provided by the user, and figure out how to split the work into tasks that can efficiently process the data set on multiple cores, and sometime in the not-too-distant future, multiple machines.
Dataflow describes queries in terms of parallel operations like filters, reducers, sorts, and so on, with streams of rows passing between them.
The query planner converts the query AST into a dataflow description; the optimizer figures out how to parallelize the dataflow while keeping computation as close to the data as possible; the compiler collapses adjacent operations into efficient runtime code (largely using closures and function pointers), and then the executor manages the running tasks and channels required to get rows flowing through the system to compute a result.
It's a popular model for database systems, so we're not blazing a wholly new trail here, but we also expect some interesting twists and turns along the way as we fit Seq's completely schema-free JSON event model and time-partitioned span-oriented storage format into the dataflow paradigm.
When will this land in an RTM version?
We're currently working to a late-2022 ship date, with a preview some time before that. As with all big changes, dates are a bit fluid, but we're gaining confidence as we tick off more TODOs, and a few more integration tests turn green 😊.
What's coming next?
Next week we'll be back to look at how expressions like startswith(RequestPath, '/api') are modeled in the query engine, all the way from a parsed AST to a native function pointer at runtime. Our plan is to then work our way down through the remaining query processing steps in future posts, sharing what we learn along the way.