Now that we've seen how Seq clusters coordinate the leader and follower roles, let's look one layer further down the stack.
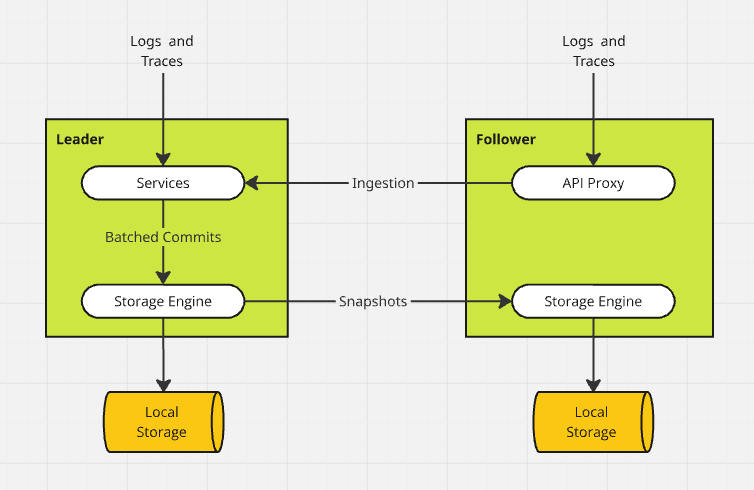
Log events and traces reach the cluster nodes via HTTP, and internally these requests are routed to the leader node. Once they reach the leader, ingestion requests are batched up if possible, and the events are committed to the corresponding data files on disk. From there, the cluster "snapshots" protocol is used to replicate data to follower nodes.
Durability
In Seq clusters, ingested events become locally-durable on the leader before acknowledgement, and are asynchronously replicated to followers. For Seq's workload, this is the happy middle-ground between "anything goes" and cluster-wide synchronous replication.
The decision to replicate synchronously or asynchronously is one we examined closely. The most predictable pressure on the replication architecture is cost, and synchronous replication reduces throughput, which translates to additional hardware requirements. Running a high-volume log server can already be a significant hardware investment, so accepting a brief replication delay in exchange for lower costs is a compelling trade-off.
In the end, log data in flight is usually ephemeral anyway: if Seq doesn't successfully ingest a span or log event, it's liable to be lost. Synchronously replicating writes would marginally increase the end-to-end durability of some events in the system, while risking the loss of others.
Although replication is asynchronous, replication delays don't impact the freshness of query results, which in normal operation always reflect the most recent acknowledged writes. "Real time" visibility of ingested data is a long-term cornerstone of Seq's design that we worked hard to maintain in clusters, too.
Data age
If the leader node does fail catastrophically after ingesting some events, but before replicating them to at least one surviving follower, those events will be lost.
Seq tracks the current replication lag on each node, and displays this in the Data > Cluster screen in the Data Age column:
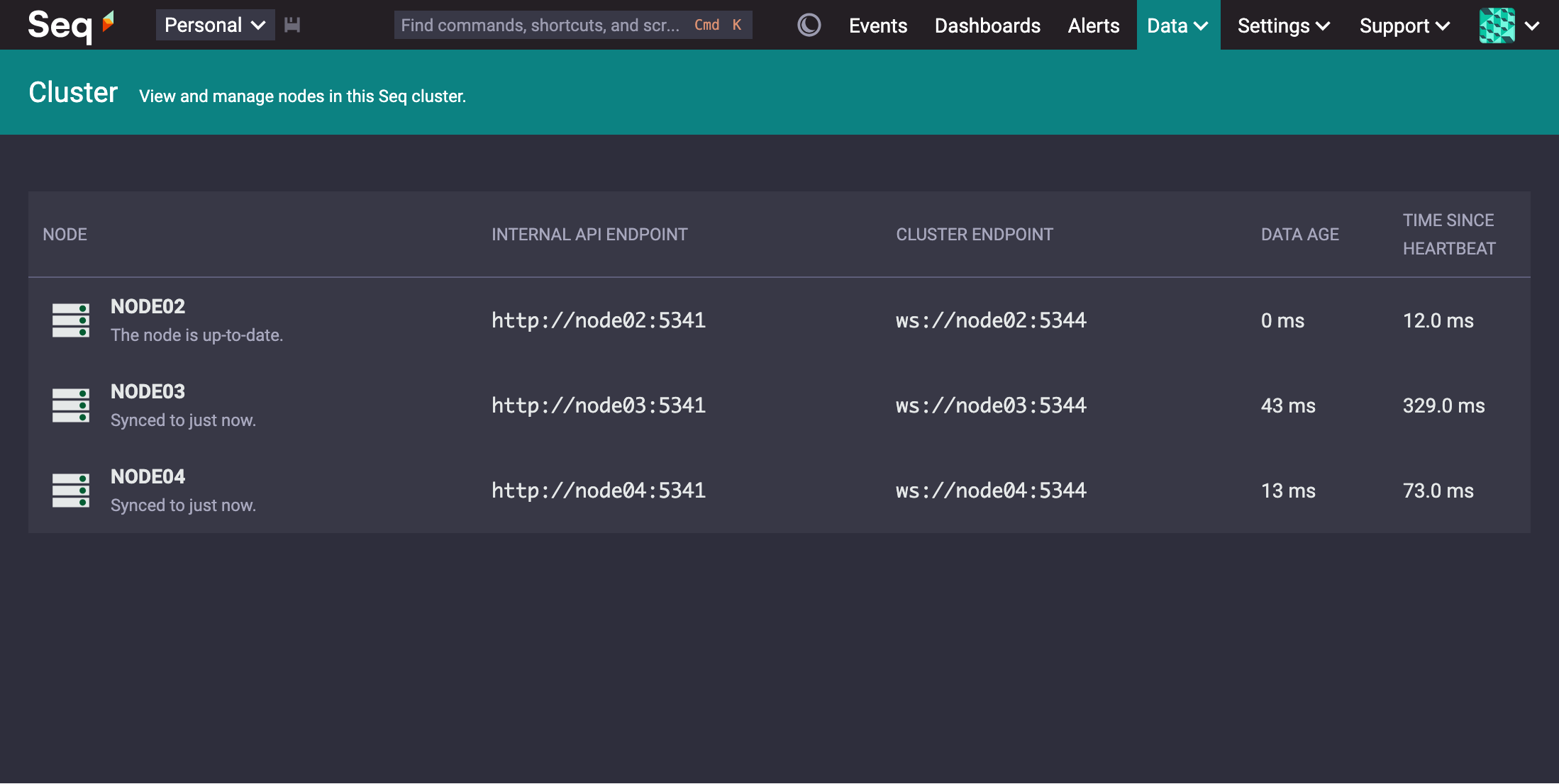
In this screenshot, which is the steady state of our tiny test cluster ingesting ~100 MB/minute on gigabit Ethernet, the data age on the two follower nodes hovers around 40 ms.
The data age across a Seq cluster fluctuates with load. It's normal to see short spikes while larger operations are replicated, but Seq will send a notification if the data age exceeds the threshold you configure in Settings > General.
The snapshots protocol
Every Seq node is networked with every other node in the same cluster. When a leader node is identified, the remaining (follower) cluster nodes need to sync their local event store to that leader. This is the role of what we refer to as the "snapshots" protocol (alongside "vertexes" and "edges" — the core work sharing protocols at the storage level).
The first goal of the snapshots protocol is to efficiently bring a follower node's event storage in line with the leader's, reusing any data already available locally on the follower.
As an extension of this, the follower needs to incrementally update its storage as the leader ingests new data or purges older data through retention policies.
The second major goal is to ensure consistency: when the follower synchronizes with the leader, the durably-committed event store on the follower will exactly match the storage on the leader at a given point in time. It's not acceptable for the follower to, say, carry some recent events ingested on the leader while earlier events are missing. Allowing fail-overs that didn't consistently match a valid state from the leader would erode trust in the data over time (did that process really not run, or did Seq just lose those events? etc.).
As it is implemented today, the snapshots protocol is based on transactional exchanges:
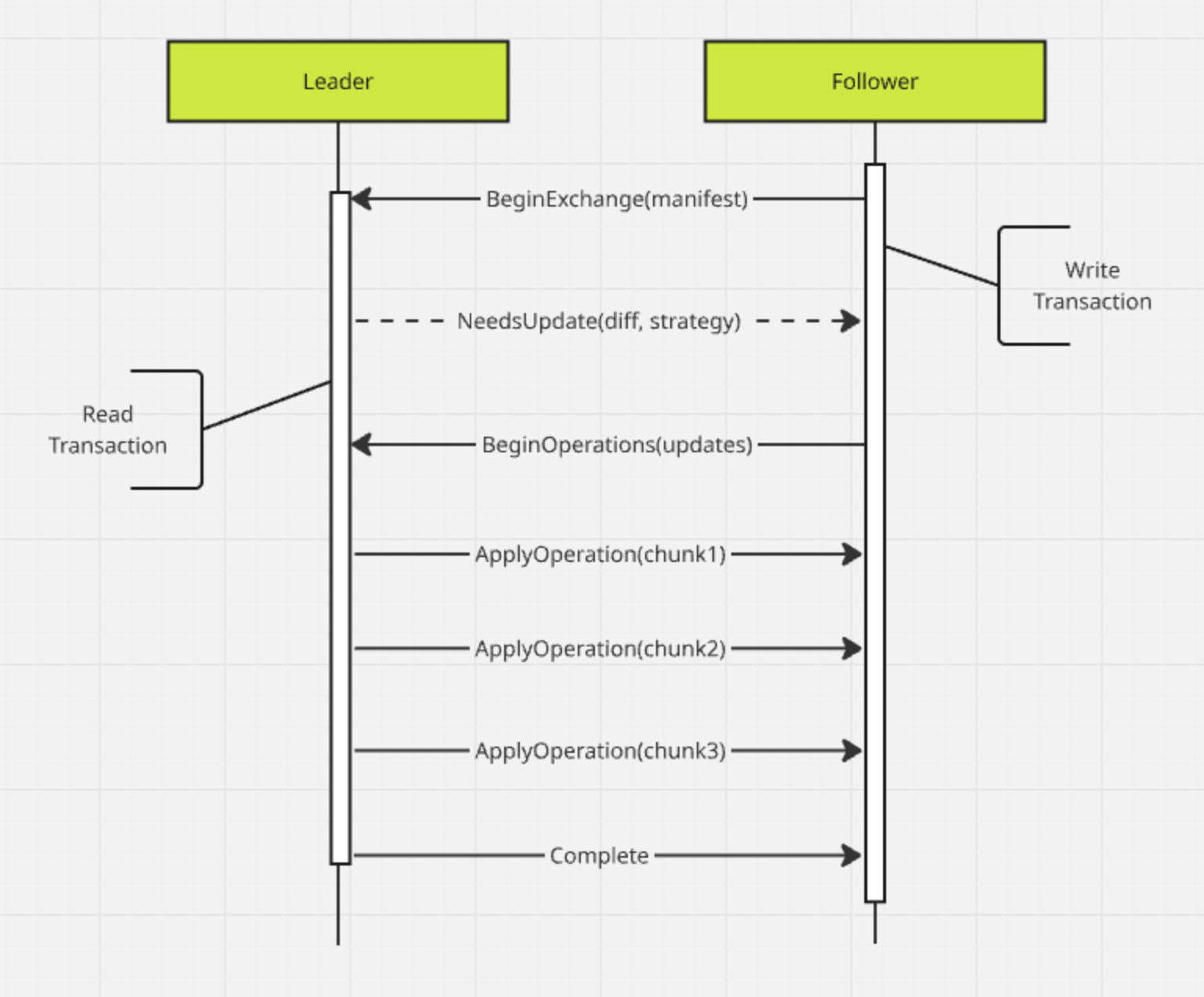
Before a follower sends anything to the leader, the follower begins a local write transaction. This prevents any unexpected local changes to the follower's state.
The follower then sends a manifest of its local event store to the leader. The manifest lists all of the immutable span files on the follower, and for each writable ingestion buffer (transaction log), the presence of the file and its committed length.
The leader, upon receiving the manifest, opens a read transaction. Read transactions in Seq's data store are snapshot-based: the transaction presents an unchanging, read-only view of the leader's local event store, and the goal of the protocol is to synchronize a follower to the latest snapshot when an exchange begins.
The leader node then diffs the manifest from the follower against its local store, and sends the difference back to the follower.
Here, the initial sync and steady state protocols diverge a little: initial syncs use a pull-based request/response strategy, while in the steady state (shown above), the leader pushes updates to the follower using a push-based/firehose strategy. In both cases, the follower receives all of the necessary data from the leader and flushes this to disk before committing its write transaction.
During this process, read transactions can still begin and end on the follower, and these will see the state of the store prior to the follower's write transaction being started.
Subsequent exchanges optimize the process a little, because the follower no longer needs to supply a full manifest to the leader in order to kick things off: the leader keeps a copy of the "to" manifest it generated in the last sync exchange, and unless the connection between the two nodes fails, this will be the follower's "from" manifest at the beginning of the next exchange.
Building on replicated snapshots
This protocol is intended to be as simple and robust as possible. Distributed systems are hard, and we've taken the position that, instead of building one monolithic clustering protocol with a rigid set of properties, we'd invest in simple, orthogonal building blocks like this one, that can evolve or be replaced as Seq itself continues to evolve.
We'll see in the next and final post of this overview how work sharing fits into that picture.