Now in preview, Seq 2025.1 introduces high availability (HA), scale-out clustering in the Datacenter subscription tier.
- Seq 2025.1 clusters continue ingesting data and serving queries even when one or more nodes fail.
- Indexing and query processing are distributed across all nodes in a cluster for higher performance.
Seq is the private, secure, self-hosted server for centralizing structured logs and traces. Receive diagnostics from OpenTelemetry and other log sources, then monitor applications and hunt bugs using an ergonomic query language — without any data leaving your infrastructure.
Compared with single-node Seq deployments, Seq 2025.1 clusters reduce downtime due to maintenance, restarts, and failures affecting a single machine. Clusters replicate event data to multiple nodes for redundancy purposes, so that data loss is minimized even when a node goes permanently offline.
Being able to scale out, in addition to scaling up, makes Seq more flexible for deployment in environments with hard physical or practical limits on the size of any one machine.
If you're looking to scale Seq, or planning to upgrade from a Seq 2024 DR cluster, read on! We're on track to ship Seq 2025.1 this quarter, so now is a great time to take a look and send us your feedback.
High availability
What happens when a cluster node is shut down? Here in the Seq office (in sunny Brisbane, Australia), we have a tiny test lab that can demonstrate the answer. Here it is, quietly humming away beside a spare desk:

These are Intel Core i5-14400/16 GB DDR5-4800MHz/512 GB PCIe 4.0 NVMe machines, running Windows 11 Pro, on gigabit Ethernet. Not servers by any stretch of the imagination, but a useful low-power test bench to keep running — and poking at — around the clock. Although we also test on cloud infrastructure, isolated, physical hardware takes a lot of friction and unpredictability out of this kind of work.
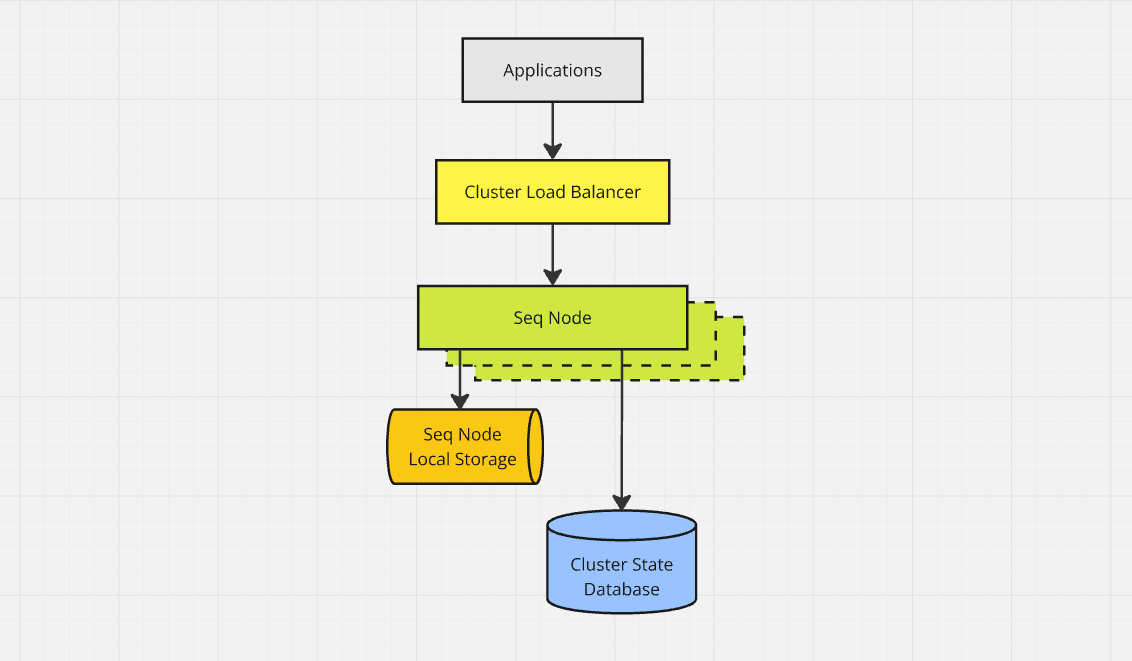
NODE01 serves as a load balancer (haproxy), shared configuration database (Microsoft SQL Server), ingest generator (seqcli), and diagnostic collector (a separate Seq instance).
The other three nodes run Seq 2025.1:
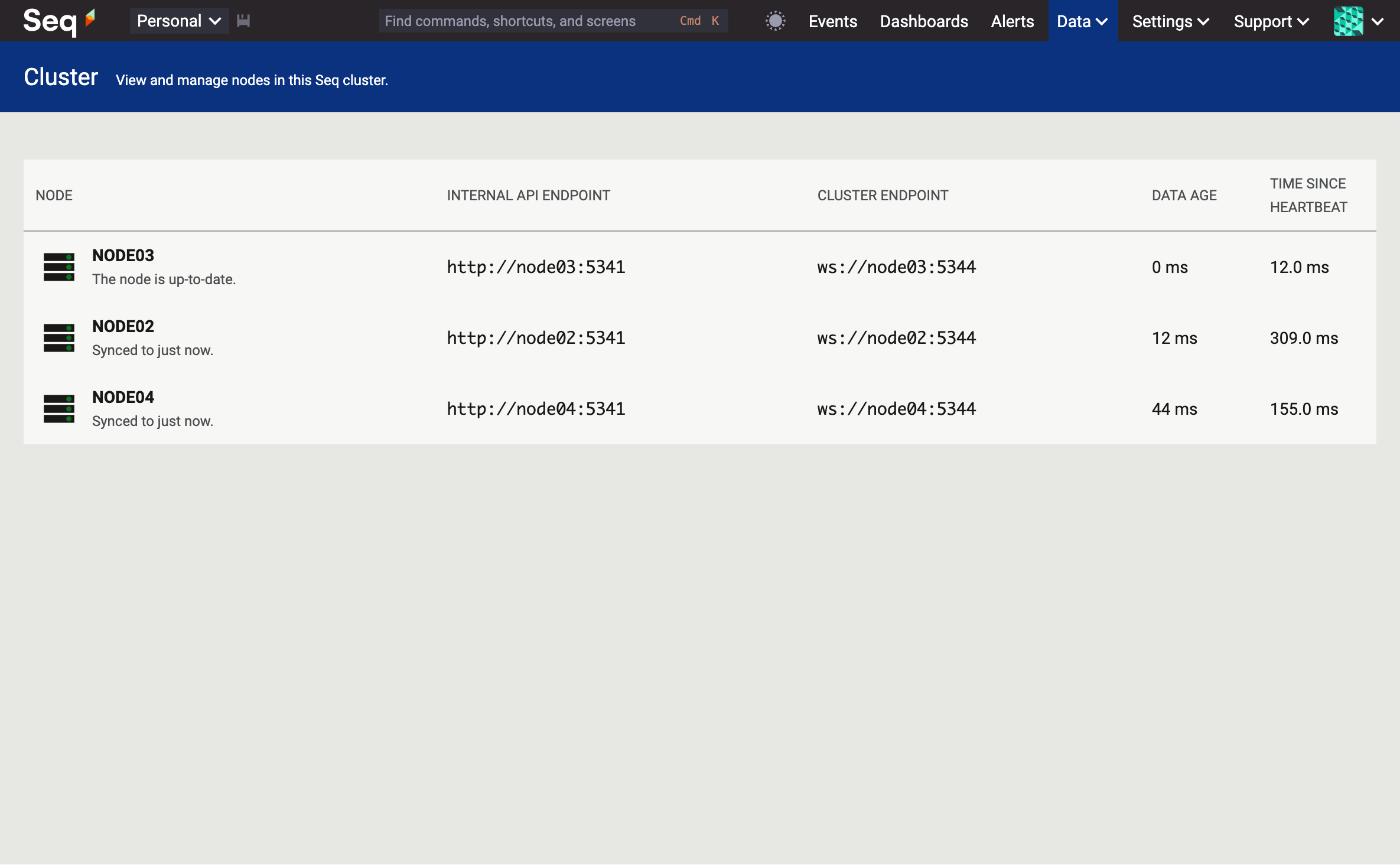
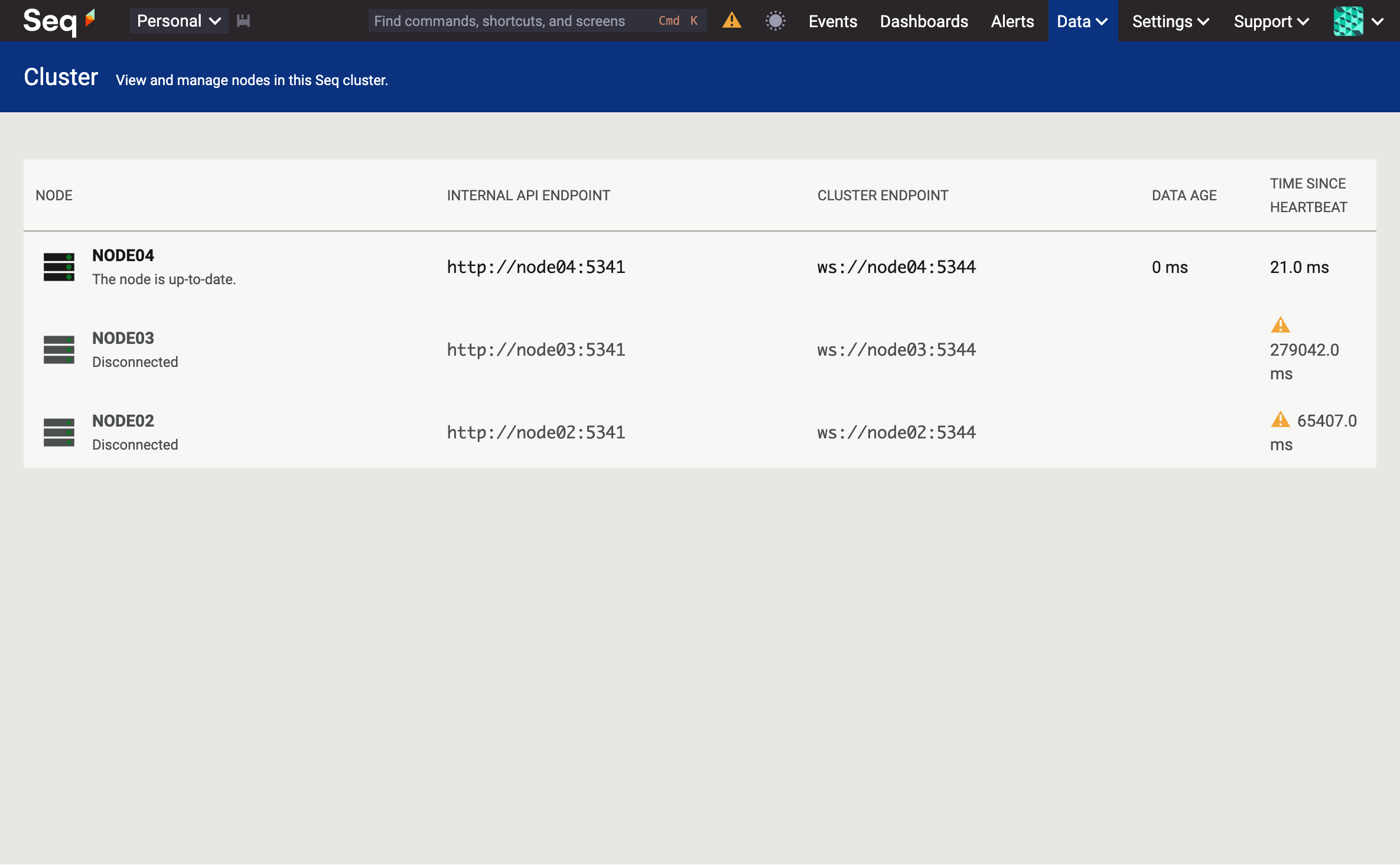
The screenshot above is a browser session being served by the load balancer. Looking closely, NODE03 is the current cluster leader, so let's gracefully shut it down...
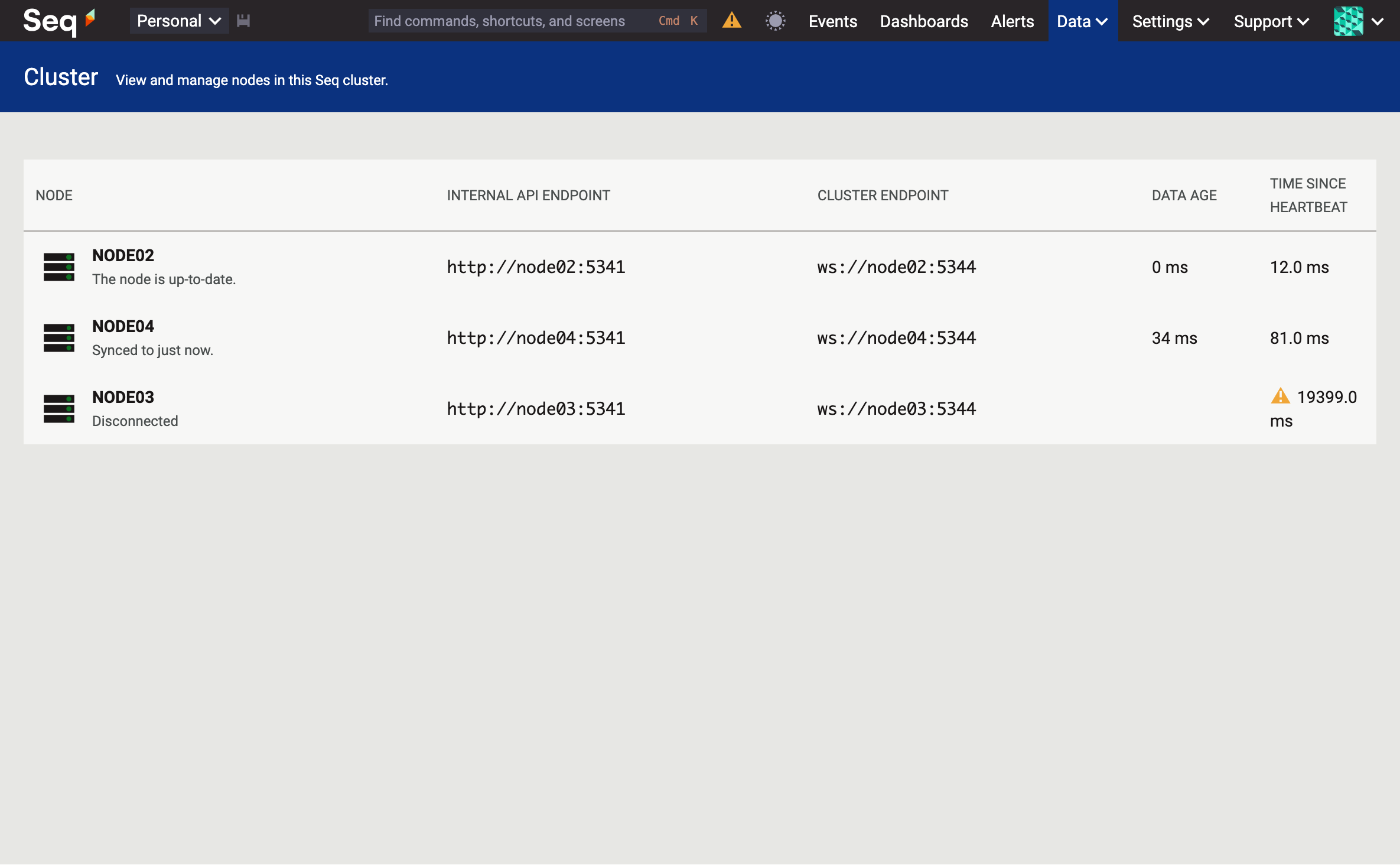
The cluster is still alive, and NODE02 now appears to be leading. There wasn't a perceivable availability gap, but I'm sure behind the scenes there were a few milliseconds in which requests might have failed in the hand-over between nodes.
What about if we hard-terminate the new leader? This is where physical machines are really great. One gentle tug on the power cord.... 👹
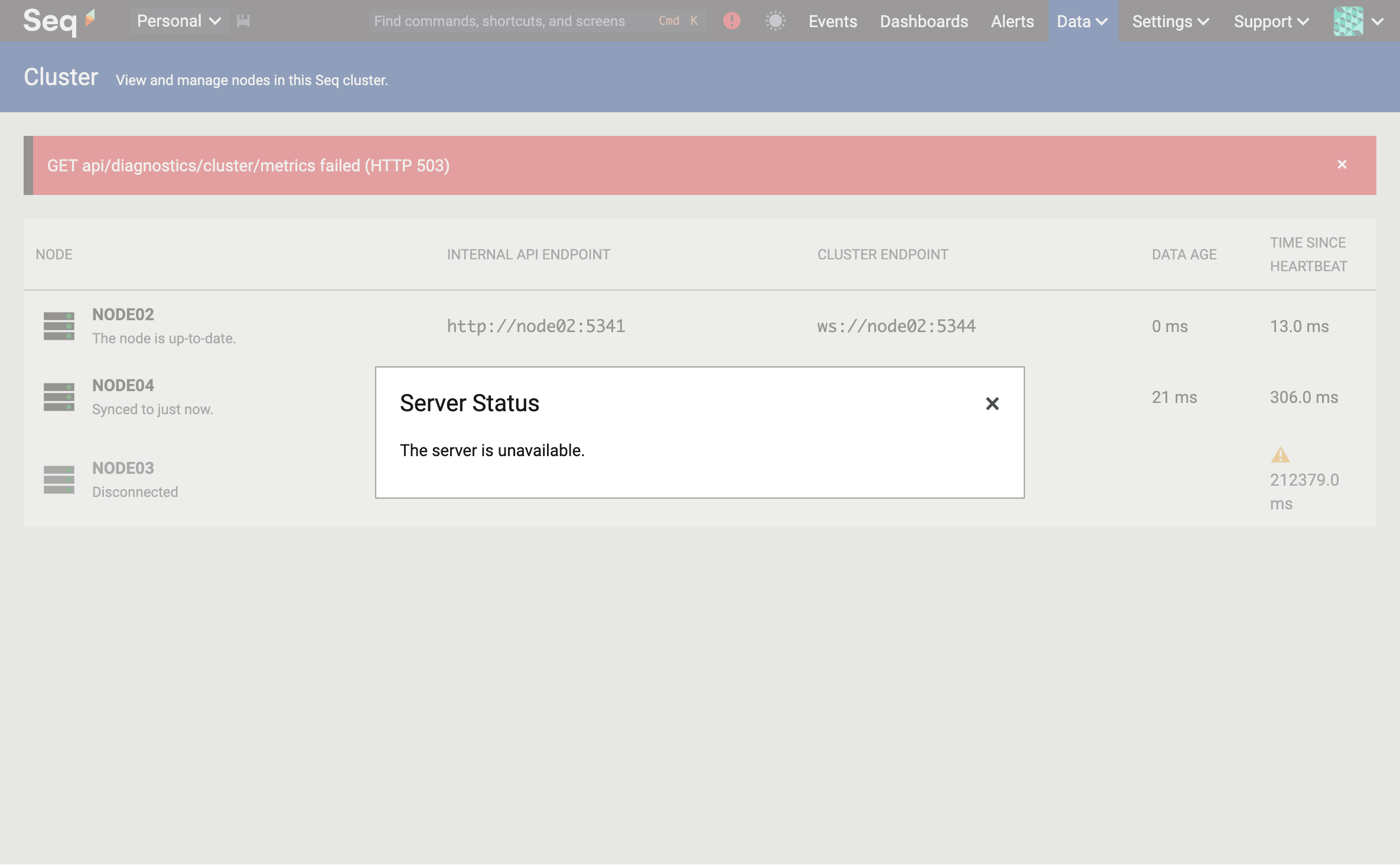
Oh! The Seq UI says that our cluster is offline. What's happening?
The cluster leader is granted a short lease, during which no other node may elect itself. Hard termination of the current leader won't clear this out: we need to wait a moment for the lease to expire. A few more seconds and...
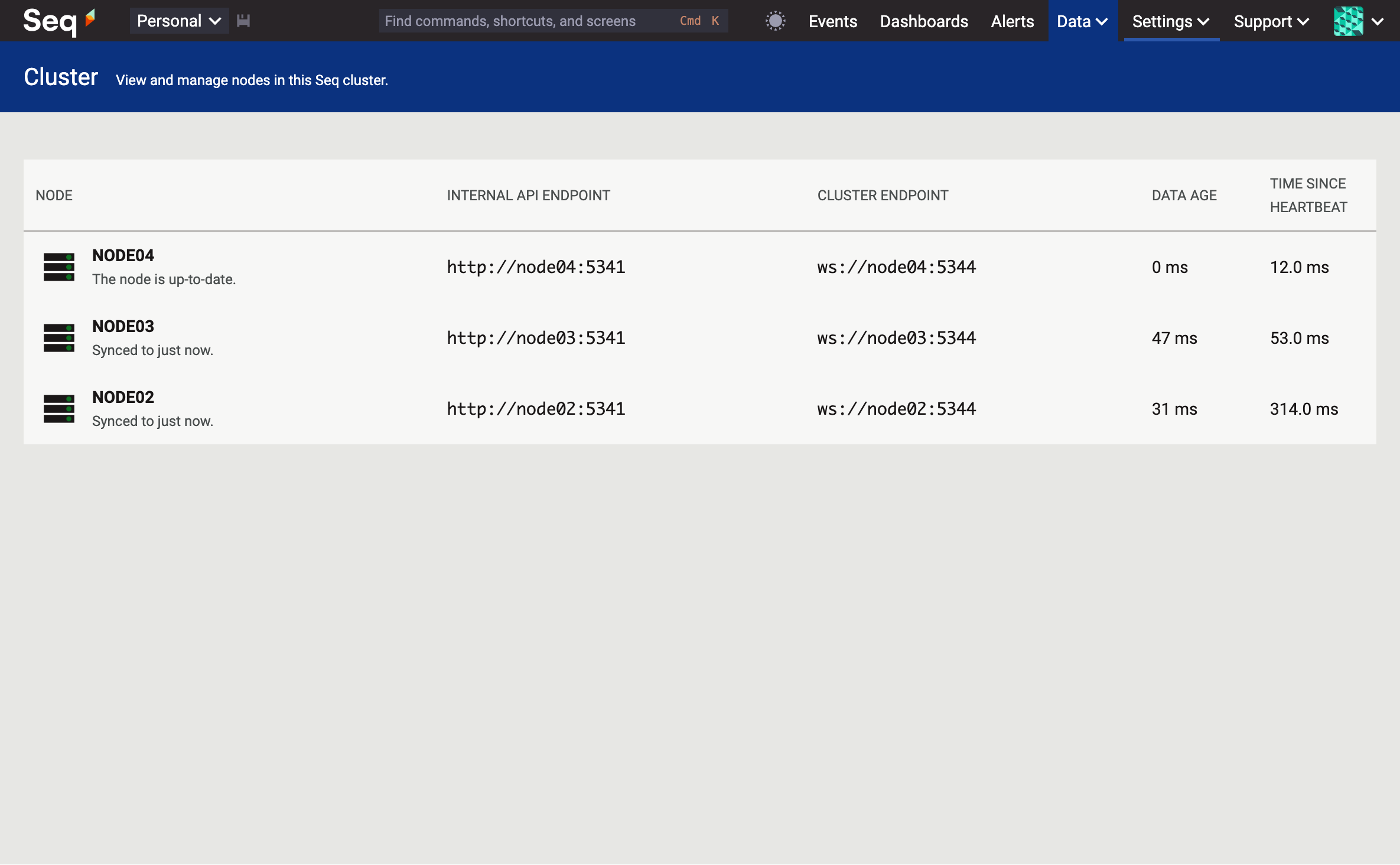
Back in business! Because Seq leans on the shared PostgreSQL or SQL Server instance for cluster state consensus, the single remaining node can elect itself leader and continue on.
Is one node a safe configuration to run? All distributed systems face various design trade-offs, and Seq is no different. Because Seq is purpose-built for live application diagnostics, it prioritizes availability over durability: when systems start going offline, your log server has to stay up, even if this means ingesting log data without replicating to other nodes (though system notifications will let you know about it 😇).
Bringing the other two nodes back gets the cluster in sync, and away we go.
Scale-out
Okay, we have three eager little machines ready to chew through our logs and traces on command. How much data are they storing?
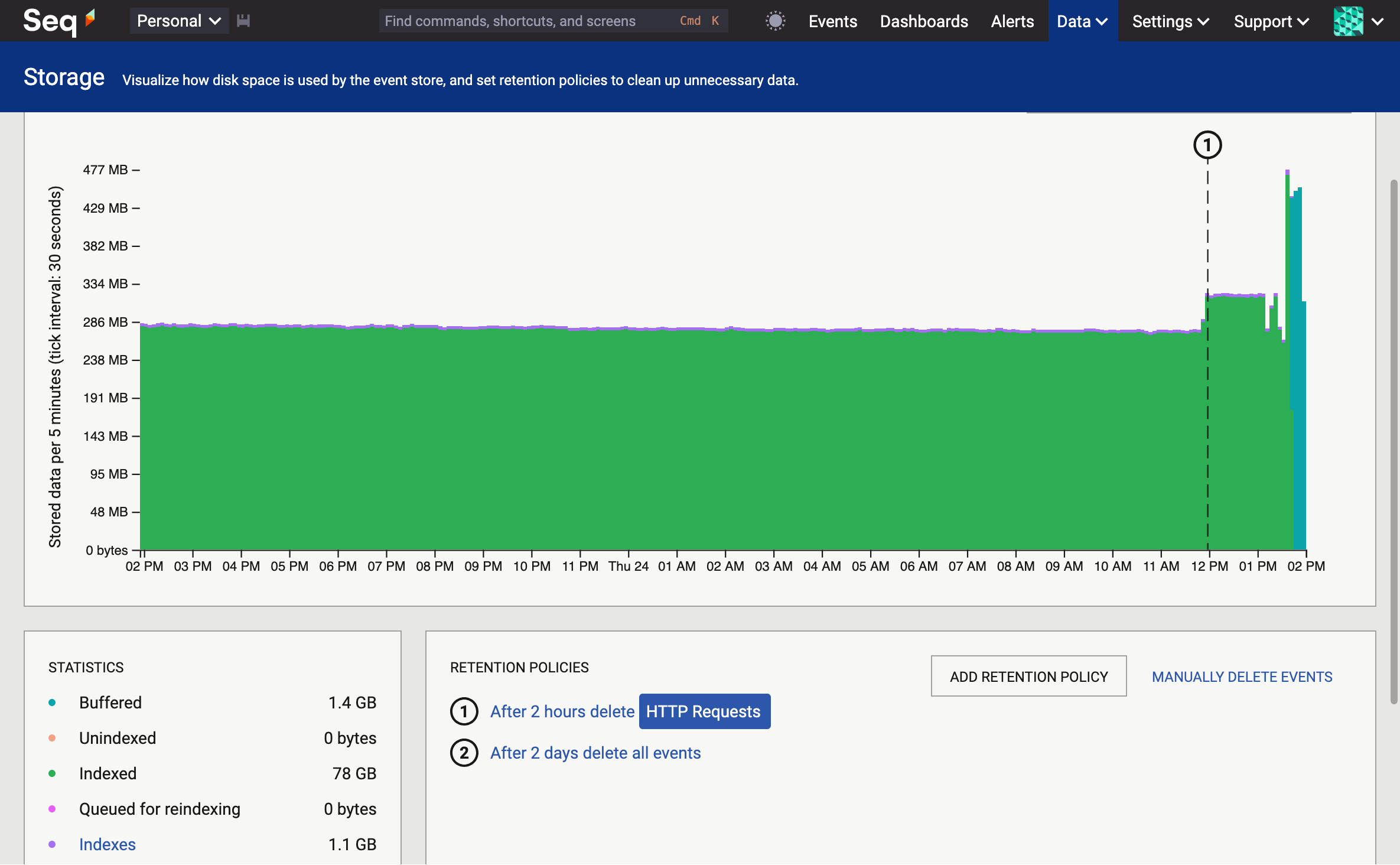
In the last day, they've ingested 79 GB, which is a respectable event stream for these little Core i5 machines to handle.
First, let's run our sample query with the cluster scaled down to one node:
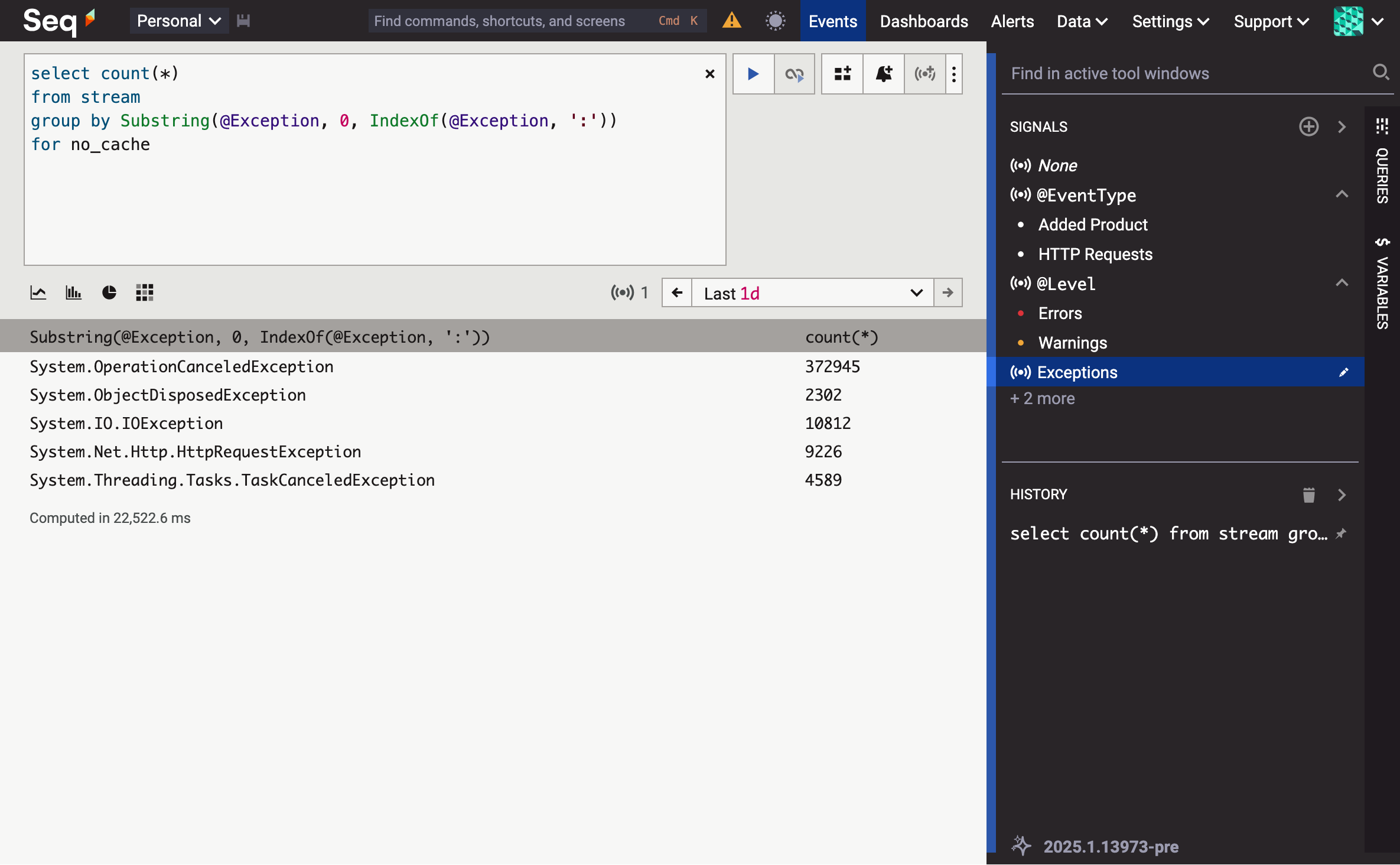
The best of three runs is 22.5 seconds.
I've chosen this query because it doesn't gain much benefit from indexing, and chews through quite a lot of string processing. Scaling out sub-second queries isn't as exciting! The for no_cache clause disables Seq 2025.1's (practically magical) partial result set memoization, to make this a fairer test.
Now, we'll bring the second node online, for a total of two active nodes:
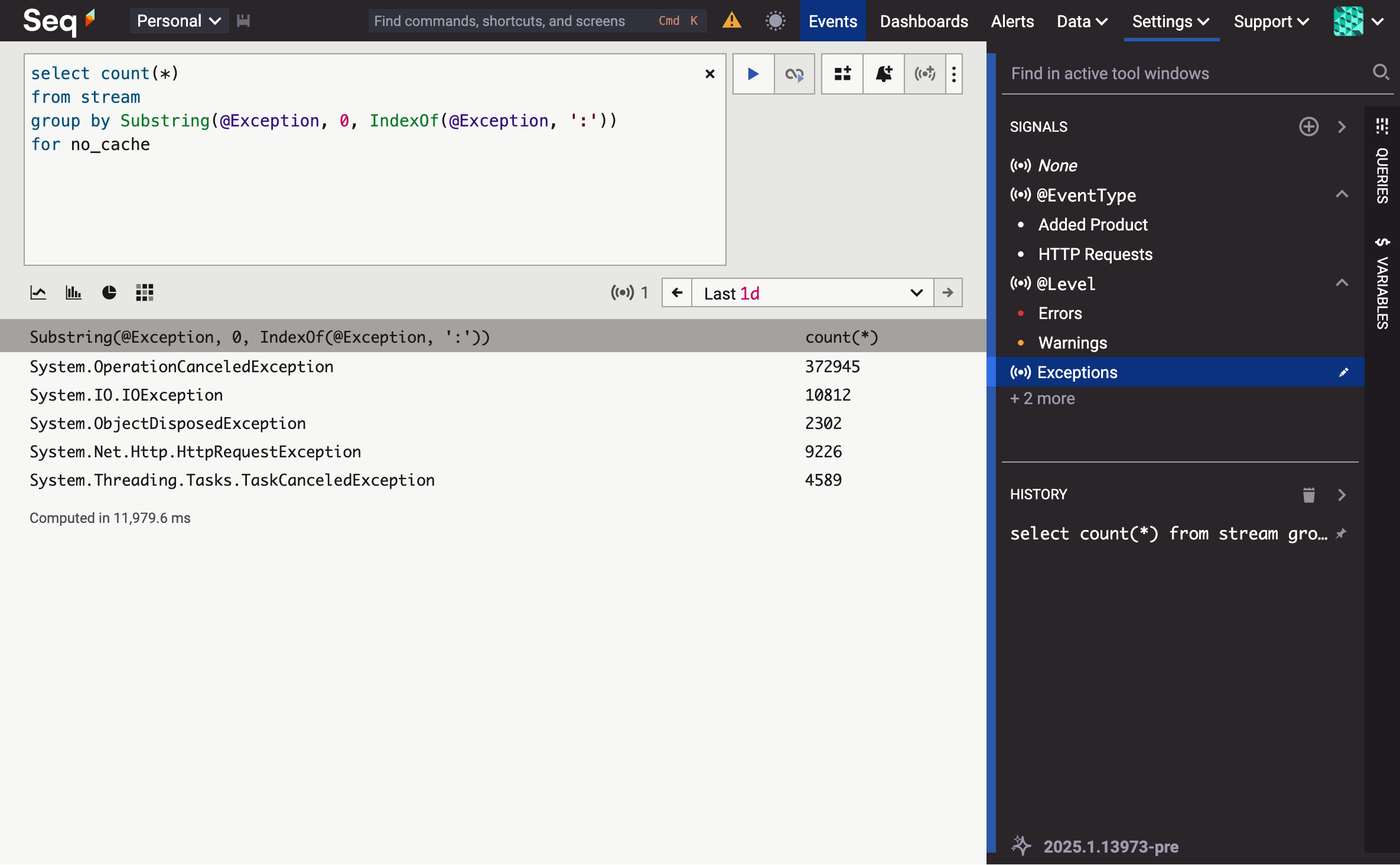
Just under 12 seconds. And with all three nodes hard at work?
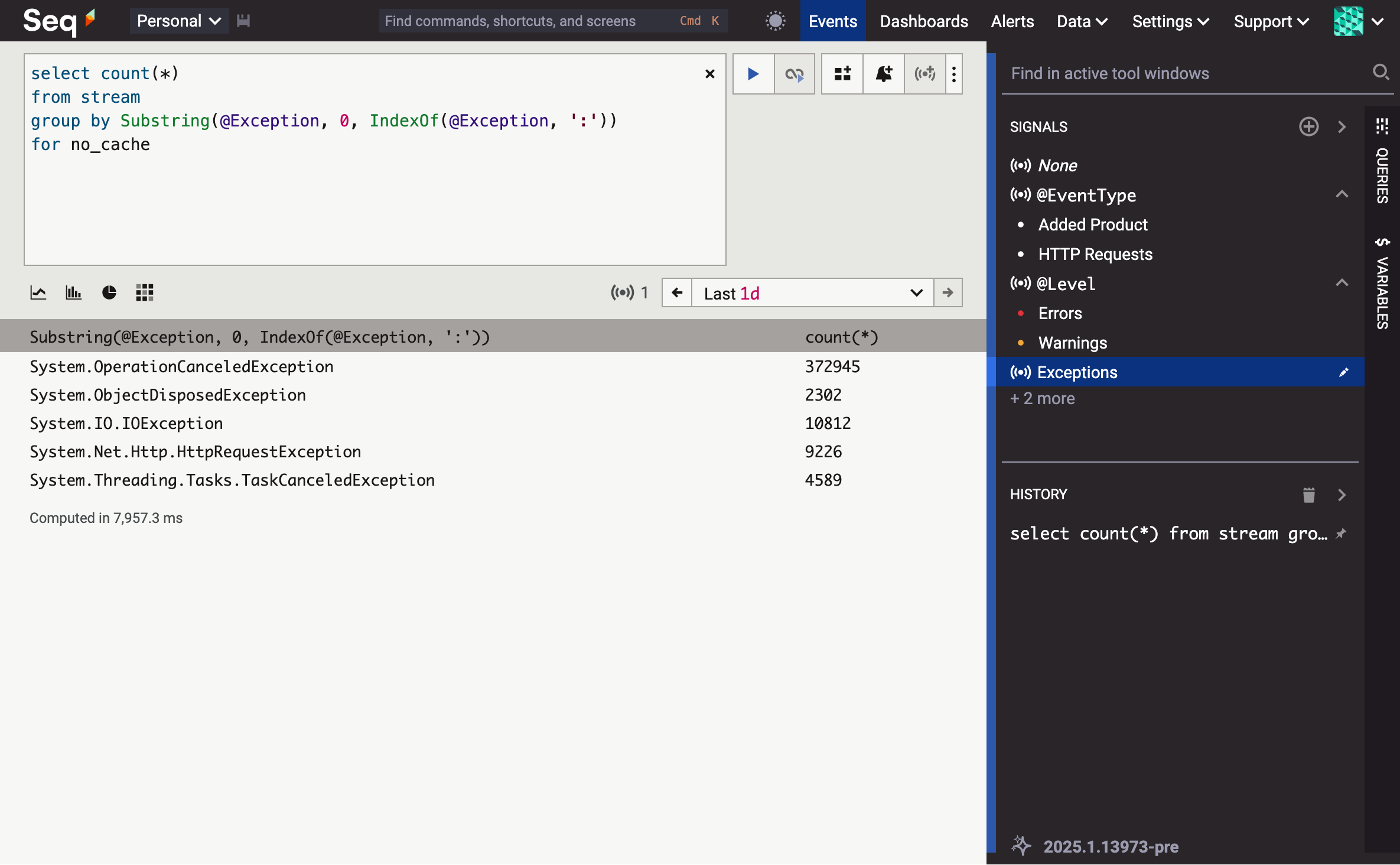
Eight seconds, which is a 2.8× speed-up over the single-node configuration.
While scaling out practically never equates to a linear performance boost (it takes work to distribute work!), queries achieve substantially better performance on the cluster.
We recommend deploying an additional, small, single-node Seq instance alongside the cluster to receive performance data and diagnostics from it. If we pop over now to the diagnostic instance for our cluster, and look for the query we just ran, we can see how it's been broken up and executed over the three cluster nodes:
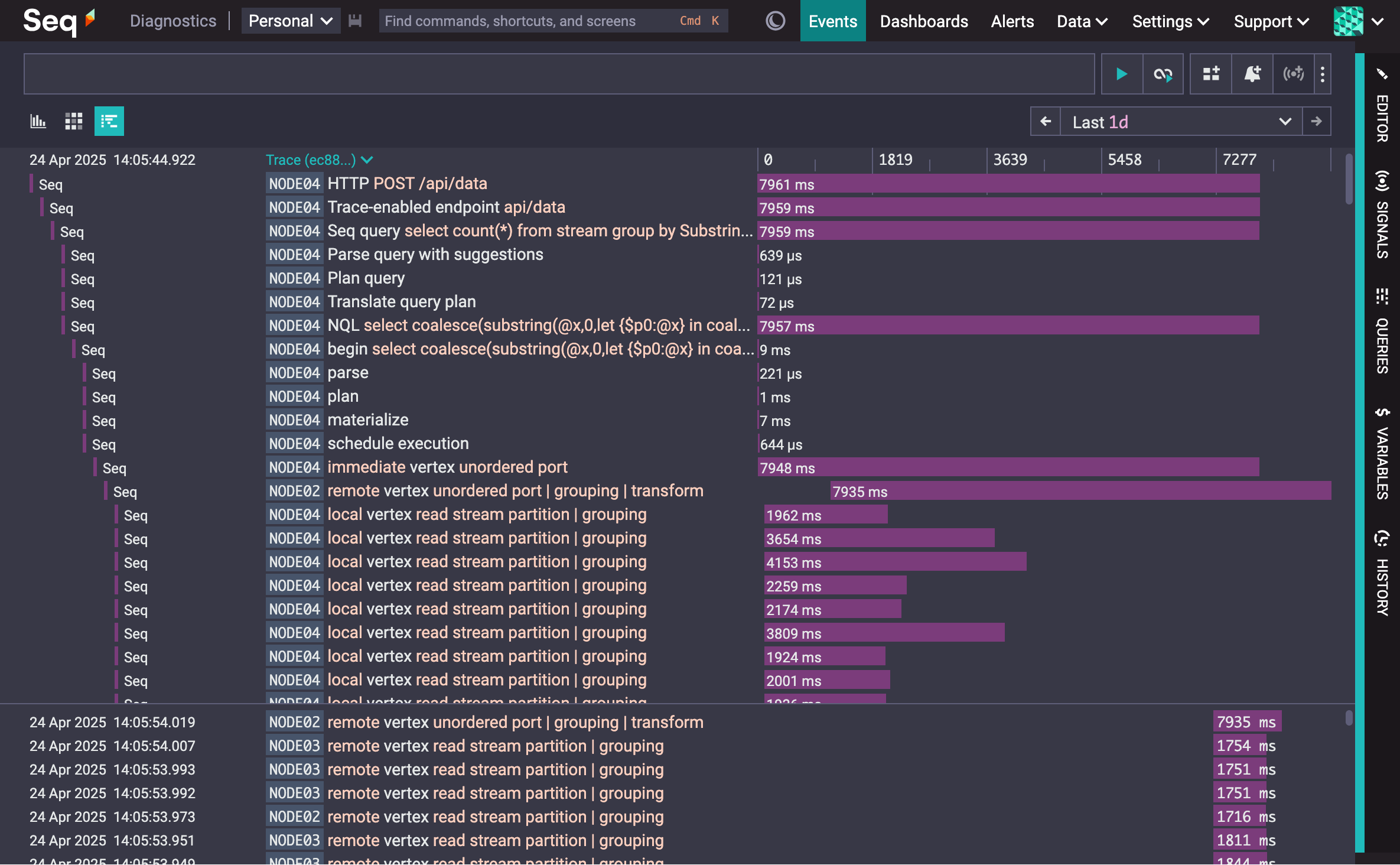
It's hard to tell what the distribution of work was just by looking at the first few lines of the trace, but running a query to add up processing time for leaf vertexes on each node gives us a better break-down:
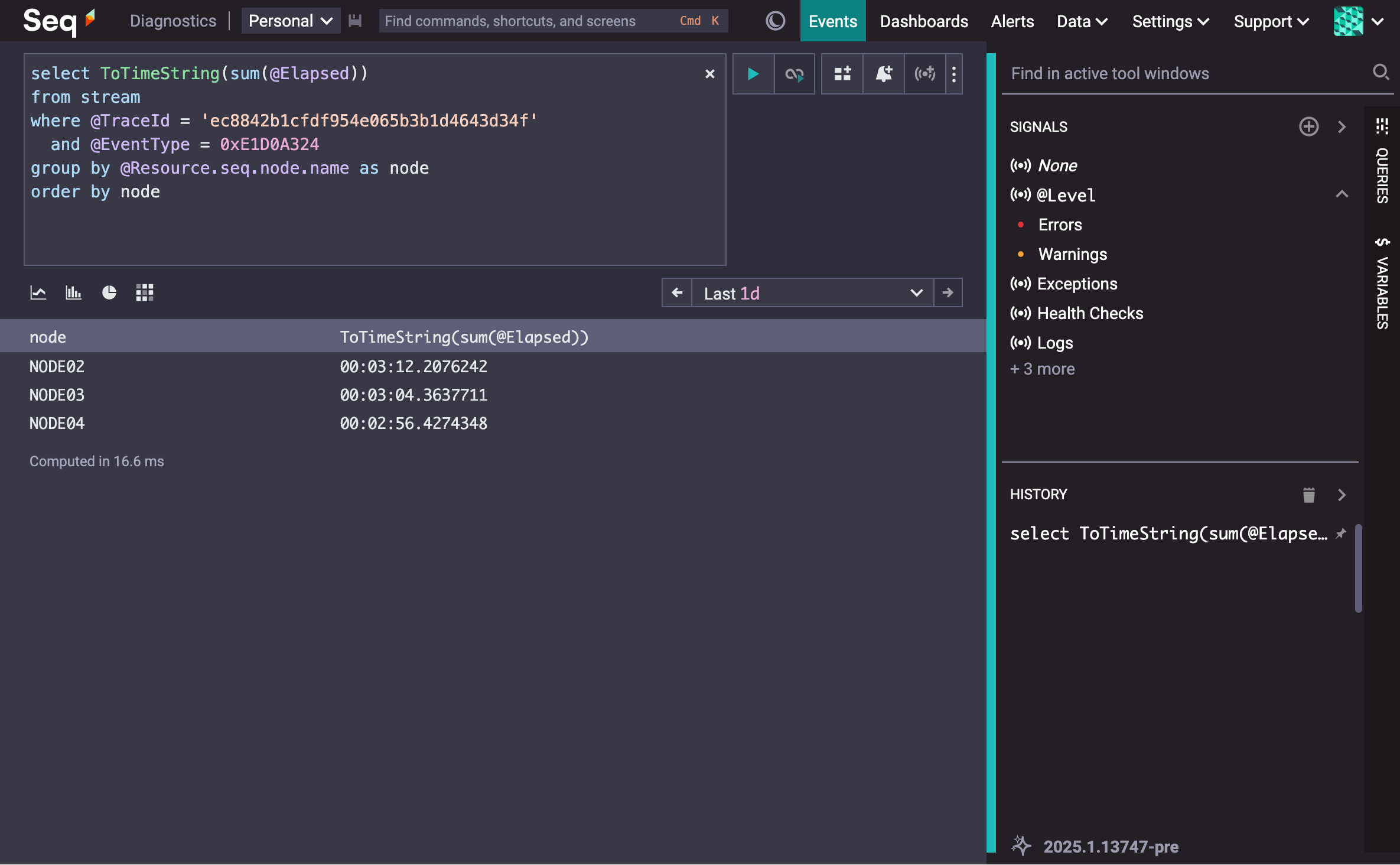
At least in terms of the spans we recorded, the distribution of work across the three nodes is fairly even.
Configuring a Seq cluster
Preview binaries are available from https://datalust.co/download (look for "preview"), and from Docker Hub as datalust/seq:preview. We've published fairly comprehensive documentation detailing how to set up a Seq 2025.1 cluster in the 2025.1 documentation collection:
https://docs.datalust.co/v2025.1/docs/clustering-overview
Configuring a cluster will require a Datacenter license, or a trial certificate from https://datalust.co/trial. Ports, paths, and a few of the finer details make deployment slightly trickier than for a single Seq node, so if you're keen to try this out but need some help getting off the ground, please just drop us a line to support@datalust.co.
Upgrading from 2024 DR pairs
If you're running a Seq 2024 disaster recovery (DR) pair today, you'll need to follow some additional instructions to upgrade to Seq 2025.1. The documentation covers these, but we'd prefer that you contact us ASAP so we can help prepare for the upgrade, and be on hand to ensure it goes smoothly.
Seq's DR support is completely replaced by the new HA implementation, which is a superset of its functionality. HA clusters are easier to manage and maintain, and make much better usage of allocated hardware. This release really is for you!
When is it coming?
Seq 2025.1 is in preview now, and we're aiming to ship a release this quarter (Q2, 2025) with clustering included in the Datacenter subscription tier.
Your feedback is vital, and we'd love to hear from you either in the comments below, or by email at support@datalust.co.