TL;DR: Seq's new query engine uses CPU cores and memory more intelligently. It's ready to try in non-mission-critical environments, and we're eager for your feedback!
We put enormous effort into making Seq queryable in open-ended ways.
It's one thing to store and index gigabytes of log data, but another to slice through it intuitivey on the tail of a nasty bug. Production debugging is all about exploring hunches and following leads, whether that's searching for text, digging through structured objects and arrays, or chomping strings with regular expressions.
Seq 2023.1 introduces a new parallel dataflow query engine, custom-built in Rust, to make open-ended queries over real-time log data faster.
- Fine-grained parallelism — the new engine can parallelize many more searches and queries, over many more cores.
- Fewer, shorter GC pauses — moving data-intensive caching out of .NET means no more multi-second availability gaps caused by heavy GC on large heaps.
- Alignment with container runtimes — the new design allows the underlying OS to manage memory pressure by evicting cached pages; this reduces Seq's reliance on OS APIs for estimating available RAM and memory pressure, which are often unreliable in containerized environments.
- Better index utilization — searches over recent data now use signal indexes when available; this can lead to orders-of-magnitude response time improvements when indexes are sparse.
It's taken us the best part of a year, but the higher ceiling for vertical scalability, and better performance from the same hardware, are well worth it.
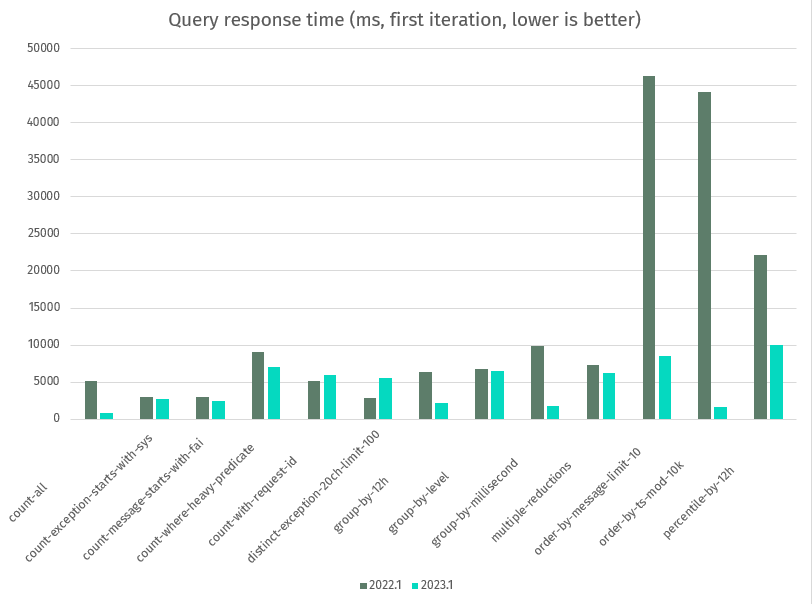
seqcli bench, unindexed, 7 days from a 30 day, 100 GB stream on AWS Graviton,im4gn.4xlargeinstance type, 16 cores, 64 GB RAM. Cases; method discussed below.
The chart above shows query performance over unindexed data. An indexed search comparison is more impressive, but less informative because of the extreme influence of index density.
For illustration, though 😊, a text search over the Warnings signal in the full 100 GB data set takes 2 minutes, 20 seconds with Seq 2022.1 on this hardware — and 0.8 seconds 🔥🔥🔥 with 2023.1.
From here to RTM
Today's beta release will help us build confidence that Seq 2023.1 captures all the important assumptions and edge-cases from the earlier versions.
If you have a non-mission-critical environment that you can deploy Seq 2023.1 into, your feedback on correctness, performance and stability will be an invaluable contribution to this release.
If all goes to plan, this will be the first and only significant 2023.1 beta, and we'll follow up with an RC and stable versions during February. We're ready to release further betas if anything unexpected appears during the first beta period.
Upgrading and rolling back
We've deliberately kept Seq 2023.1 highly-compatible with Seq 2022.1. If you're not already running Seq 2022.1, it's best that you update to that version and use it for a few days before continuing.
On Windows, upgrading is as simple as running the Seq-2023.1.8757-pre.msi installer from the Seq download page. On Docker, restarting your Seq container on the datalust/seq:preview image will cover everything that's required to start using the new version. You won't notice a lot of UI differences: to be sure you're running the new build, you can refresh your browser window and check the version displayed in the Support navigation bar menu.
Downgrading is the reverse of upgrading. On Windows, you'll need to uninstall Seq from the Programs and Features menu before reinstalling 2022.1 (uninstalling only removes program files, not data). On Docker, switching back to datalust/seq:latest is sufficient. As always, you can contact us via support@datalust.co if you need help with any part of the process.
Breaking changes
These are breaking changes expected in 2023.1:
- Seq's HTTP API no longer exposes diagnostic counters for the event cache.
min()andmax()now operate on all data types, not just numbers; if you're relying on these aggregations implicitly filtering out non-numeric data, you'll need to update your queries to work around this.
Benchmarking before-and-after
The latest seqcli 2023.1 preview binaries include a new seqcli bench command that runs a set of predetermined benchmarks against a target Seq server. Downloading the seqcli binaries and running seqcli bench before and after the upgrade will produce output that can be used to get a rough idea of how the new version will compare on your hardware.
〉./seqcli bench -s http://ec2-34-219-98-48.us-west-2.compute.amazonaws.com --runs 3 --start "2023-01-10T00:00:00Z"
[15:15:49 INF] Bench run 4d5f3e872d364cd6 against http://ec2-34-219-98-48.us-west-2.compute.amazonaws.com (2023.1.8757-pre); 13 cases, 3 runs, from 01/10/2023 10:00:00 to null
[15:15:52 INF] Case count-all mean 758 ms (first 781 ms, min 745 ms, max 781 ms, RSD 0.03)
[15:16:01 INF] Case count-exception-starts-with-sys mean 2,673 ms (first 2696 ms, min 2,638 ms, max 2,696 ms, RSD 0.01)
[15:16:09 INF] Case count-message-starts-with-fai mean 2,564 ms (first 2514 ms, min 2,514 ms, max 2,611 ms, RSD 0.02)
[15:16:31 INF] Case count-where-heavy-predicate mean 7,113 ms (first 7067 ms, min 7,064 ms, max 7,208 ms, RSD 0.01)
...
When comparing 2022.1 and 2023.1 using seqcli bench, the first query response time is a better comparison to make; 2022.1 will always cache time series query results by default, while 2023.1 reduces memory use by doing this only when rendering dashboards. That means subsequent benchmark runs on 2022.1 will use cached data, throwing off measures like the mean and minimum response times. In practice, we think 2023.1 makes better trade-offs, here.
We'd love it if you are able to send the results to support@datalust.co, along with some information about your hardware and log volume. 💌
Reporting bugs and regressions
The best place to report bugs is the GitHub tracker or our support address mentioned above. If you think you've spotted a security issue in 2023.1, please contact us via security@datalust.co.
Getting Seq 2023.1 Beta
Thanks for giving Seq 2023.1 a try! You can find the preview Windows installer at datalust.co/download and the datalust/seq:preview container on Docker Hub.