Seq 2020.1 is here!
We've been hard at work since the release of Seq 5.1 last year, and today we're excited to finally take the wraps off Seq 2020.1.

Seq 2020.1 is faster, even easier to use, and makes better use of hardware resources than its predecessor.
If you just want to dive in, download the Windows installer or pull the latest datalust/seq Docker image, and go! Seq 2020.1 is a highly-compatible, in-place upgrade from all recent versions.
What is Seq?
Seq is a self-hosted log server, designed to let any software development team, on any platform, get first class diagnostics from production apps and services. It's the solution of choice for organizations that need to own and tightly manage their diagnostic data.
Seq is a fully-integrated event store, query engine, alerting system, and web interface, built using C#, JavaScript, and Rust.
Highlights of 2020.1
Though we didn't set out intentionally to break records, Seq 2020.1 became the single biggest Seq milestone ever. Here are some of the highlights!
Go further with the same hardware 🚀
Upgrading from Seq 5.1 to 2020.1 gives you increased responsiveness, and better search performance (we've seen ~10× for some queries), from the same server hardware.
Along with improvements thanks to .NET Core 3.1, we've moved large parts of the Seq query engine from C# into Rust, reducing pressure on the .NET garbage collector and enabling more aggressive parallelism.
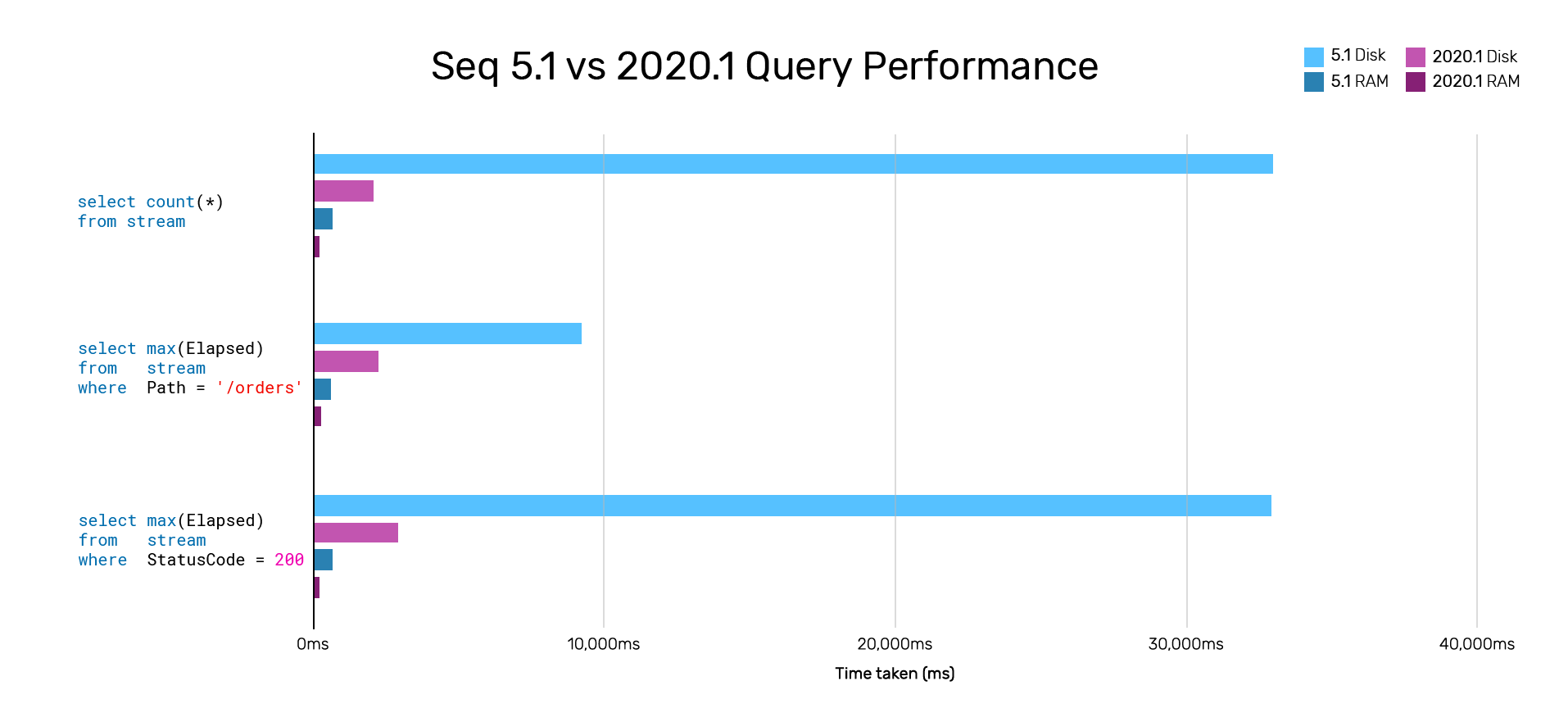
While the cache-enabled numbers (RAM) show an improvement from 5.1 to 2020.1, it's disk search has the biggest performance impact when data exceeds available memory, and this is where we've focused most of our effort. The improvements in Seq 2020.1 make a noticeable difference when running with larger machine and data sizes.
Some really interesting tech came out of this work, including a fully-vectorized, sparse JSON parser, and a new runtime for evaluating complex expressions over JSON objects. We're excited to share it with you, so watch this space for an upcoming deep technical dive into the new stack.
Authenticate with OpenID Connect
OpenID Connect is the emerging standard for authentication using OAuth 2.0. Many teams use OpenID Connect providers like Auth0 to implement single-sign-on and multifactor authentication. Thus, integration has been one of the most-requested features on our backlog.
Find out how to get started in our detailed setup guide.
Stay in control of log ingestion
Carefully managing the volume of log data ingested by Seq is crucial for keeping storage and processing costs down. Applications can behave unpredictably, misbehave, or just send more data to Seq than expected, leading to runaway disk, RAM, and CPU consumption, and reduced search performance.
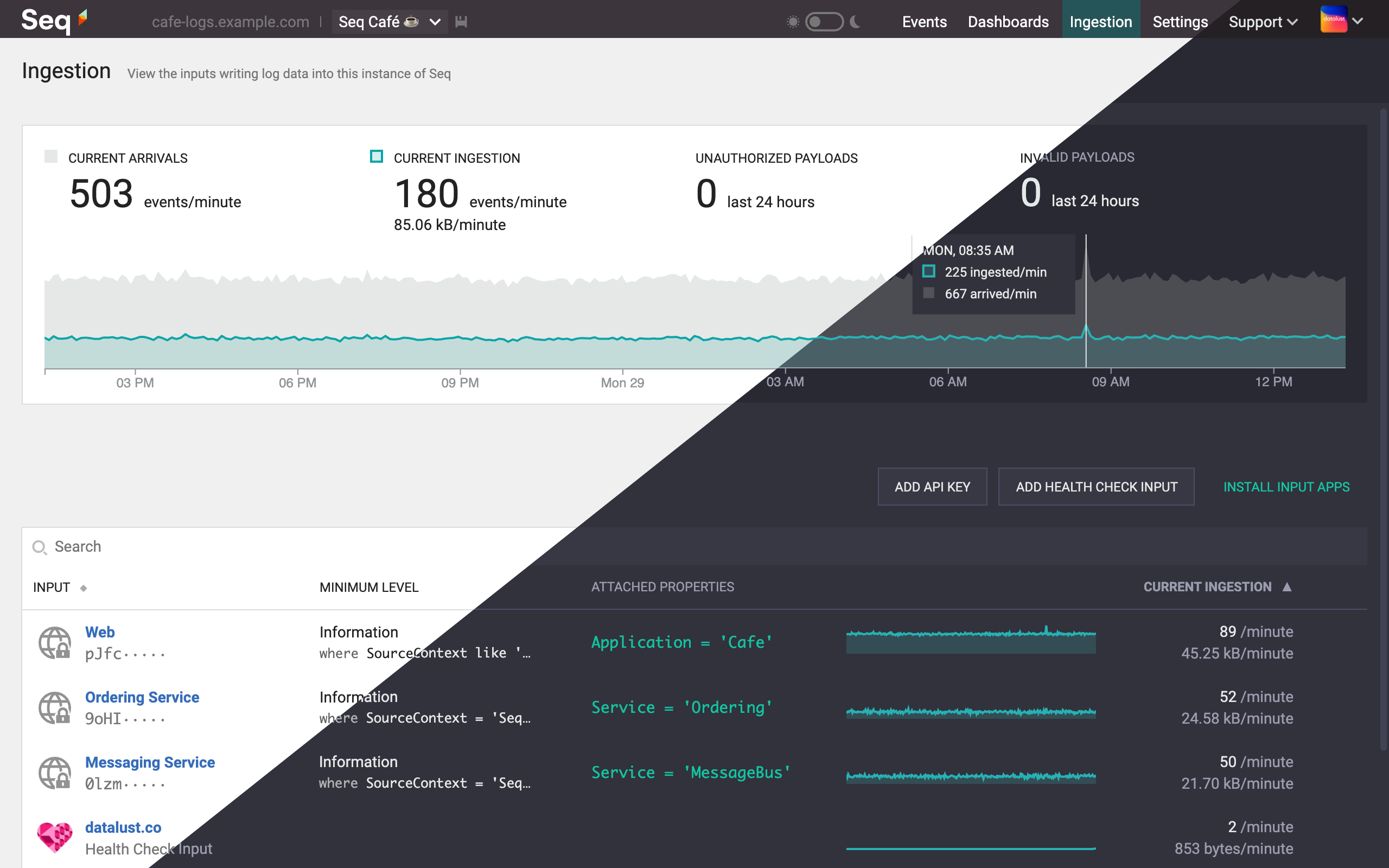
The new ingestion view shows trends and data volumes across log inputs, tracked for 24 hours, making it much easier to spot problems and filter out unnecessary noise.
Handle logs from more frameworks and platforms with ease
GELF, syslog, and other pluggable inputs are now on an equal footing with the built-in HTTP API:
- Track fine-grained ingestion metrics for each input
- Limit ingestion using minimum levels and filters
- Tag events with attached properties, and
- Use server timestamps when necessary.
Whether you're managing .NET, Java, or Node.js apps, or collecting logs directly from Docker, Seq 2020.1 provides a first-class experience.
Easily deploy Seq to Kubernetes
The official Seq Helm chart for Kubernetes has had an overhaul. Better defaults, and more features enabled out-of-the-box, make setting up Seq 2020.1 on your Kubernetes cluster a breeze.
Find more details in the Helm chart documentation.
Narrow down your search
We've added new language features to help you find what you're searching for, faster. Express an even wider variety of queries using:
- The universal case-insensitive (
ci) modifier, enabling case-insensitivegroup by, property access, comparisons, and more - Conditional expressions with
if/then/else - Object literals
{a: 'hello', b: 42} - Structural equality comparisons for arrays and objects, e.g.
EventId = {Id: 1, Name: 'UnhandledException'} interval()in queries that group bytime()select *and@Documentnow reflect the underlying JSON data model- Better error reporting for search expressions
coalesce()function with variable number of arguments -coalesce(A, B, C, ...)Keys()andValues()built-in functions for collection manipulationToJson()andFromJson()for handling JSON-encoded stringsToUpper()andToLower()built-ins- Column aliases in groupings -
group by A as b
Upgrading from Seq 5
Seq 2020.1 is an in-place upgrade for Seq 5.0 and 5.1. Most users can simply run the new Windows installer, or pull the latest datalust/seq Docker image, and Seq will take care of migrating your existing data when it starts up.
If you're running a large Seq installation, or have applications that integrate tightly into the Seq API, check out the upgrade guide for an overview of what's changed.
Learning more
There's a lot more to Seq 2020.1, and we'll have some in-depth posts to share in the coming weeks.
Our Seq documentation has had major update for this version, and is a good place to start if you're new to Seq. If you're already thoroughly familiar with Seq, and just want the details, the 2020.1 GitHub milestone has some great info.
Happy logging!