We spent the past 12 months making Seq HA-capable and able to scale work out across multiple nodes. This post is the first of three that dig into how clustering is implemented. It's not so much about using Seq, as about how it works inside, and along the way we'll touch on some of the trade-offs we chose.
Seq is the private, secure, self-hosted server for centralizing structured logs and traces. Receive diagnostics from OpenTelemetry and other log sources, monitor applications, and hunt bugs — without any data leaving your infrastructure.
From the outside
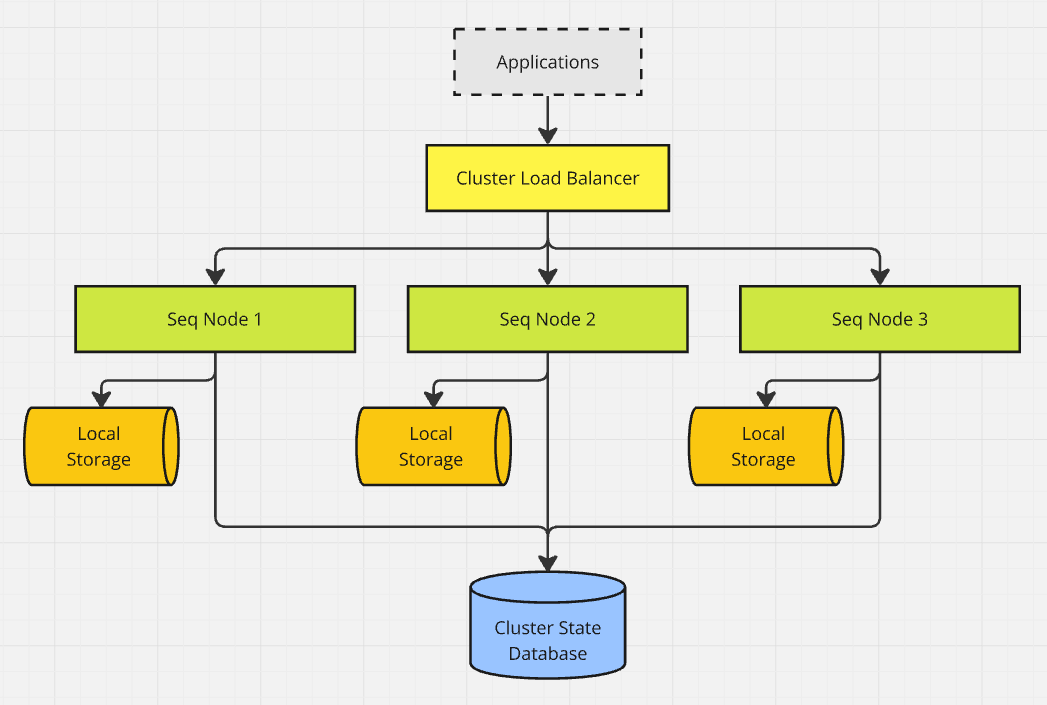
To the outside world, a Seq cluster is symmetrical. Every node can handle requests, and any node can be taken offline without disrupting the cluster as a whole.
The leader and followers
Internally, as in many clustered systems, the nodes have distinct roles that govern their behavior.
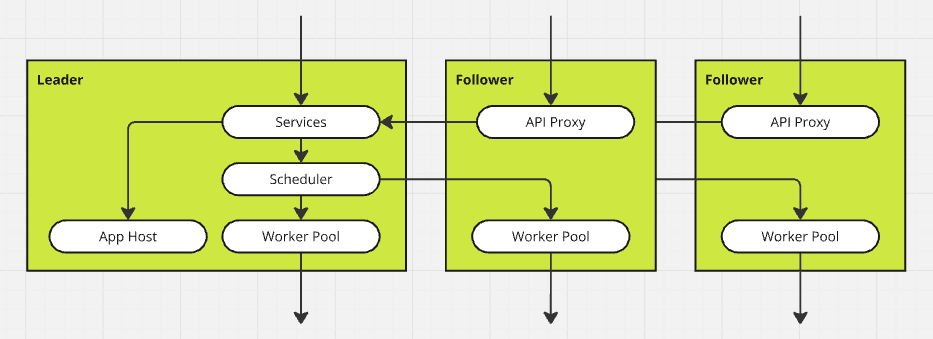
The nodes elect a "leader" from among themselves, and the remaining nodes work in the "follower" role. In a Seq cluster, the leader is responsible for:
- Committing batches of ingested events
- Evaluating retention policies
- Planning and coordinating queries
- Handling most API requests
- Running plug-in Seq apps
All nodes, including the leader, share in:
- Data storage
- Indexing
- Query execution
Follower nodes have the added responsibility of proxying inbound API requests to the leader.
Consensus
The first question you might ask about any clustered system is how the nodes in the cluster coordinate among themselves. Without any node being granted special status, it's difficult to reliably decide on anything, so the cornerstone of many clustered systems is the decision-making process referred to as "consensus". This is where you'll encounter Raft, Paxos, and a whole discipline's worth of interesting algorithms and ideas.
Seq's main use of consensus, today, is for leader election. That is, deciding from among the online nodes which of them should assume the leader role. Leader election is necessary when the cluster starts up for the first time, and when nodes are removed or lost. Leader-based systems avoid the need for distributed consensus in other layers; in our case, because Seq needs to ingest large volumes of log data with low overhead, we chose a leader-driven system so that ingestion could proceed on the leader without requiring further coordination between nodes.
Despite us having spent Christmas 2023 implementing the Raft consensus algorithm, a competing internal proposal to piggy-back consensus off the shared metadata database won, primarily because it can allow Seq clusters to continue operating right down to a single available node. Clustered SQL Server and PostgreSQL implement strong consistency, so Seq 2025.1 nodes decide on a leader by attempting to insert their id into a shared leader table, with the database guaranteeing that only one of them will succeed.
Cluster node state changes
When a leader node is elected, it is granted a "lease" during which no other node may become leader. The lease starts counting down immediately, but the leader periodically extends it so that cluster leadership remains stable as long as the consensus database is available.
There's a catch, though. The leader's activities can't be instantaneously started or stopped — a node promoted into the leader role might not even get ramped up before a network problem causes the lease to expire and the brakes have to be put on everything again. Without great care, a slow or hung leader could block up the system, or two nodes might act in the leader role even if only one of them is currently elected.
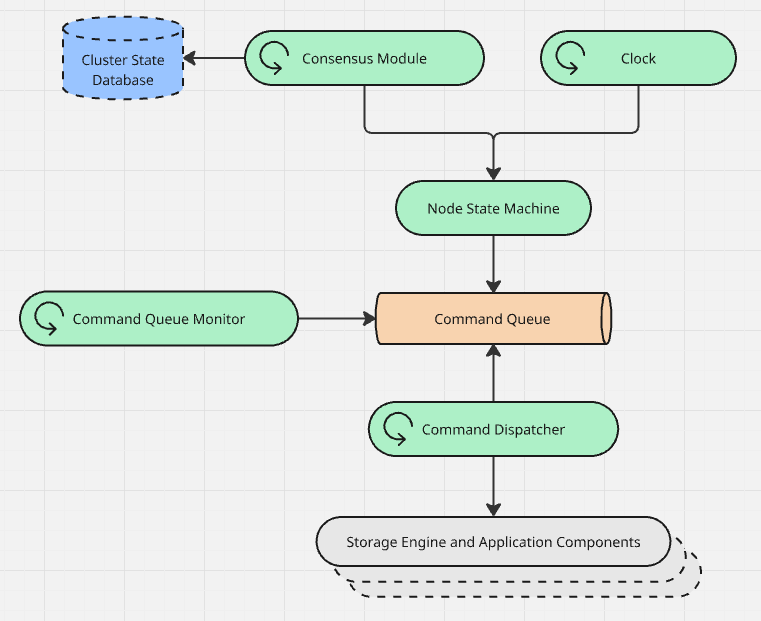
The diagram above shows how leader election drives state changes in the running Seq application layer.
Consensus Module: this component plays the leader election game against the other nodes. When the current node acquires a fresh leadership lease, or another node is determined to have gained leadership, a trigger is fired in the node's internal state machine.
Clock: the consensus module calls out to a database, so it might block or fail. All the while, the clock is ticking: this component continuously fires "tick" triggers in the state machine, so that lease timeouts can be detected.
Node State Machine: each node can be in one of several states that determine how it will behave. The state machine decides, for each input trigger, whether any action is necessary. Everything on this diagram could be viewed as infrastructure supporting the node state machine, feeding in information about the outside world and acting on the state machine's outputs.
Command Queue: the node state machine is not synchronously coupled to any other component. Instead, if a transition between states needs to have side-effects in the rest of the system, the state machine publishes commands to the command queue.
Command Queue Monitor: the command queue monitor ensures the application side of the Seq node is keeping up. If the monitor notices the command queue filling up, or spots problems like the node being told to deactivate while activation hasn't yet completed, the monitor steps in and hard-terminates the Seq process.
Command Dispatcher: Seq's application layer is typical of a .NET Core application. HTTP request handling middleware, the storage engine, and other components like the alert processor or application host, integrate with one another using dependency injection. When the cluster state machine spits out a command, the command handler dispatches this to the application layer components that need to respond.
The running cluster
Zooming back out, the components here are responsible for safely getting and keeping the cluster running as individual node start up, shut down, or fail.
In the next post, we'll drop down a layer and look at the native storage engine's replication protocol, which copies data redundantly to each cluster node to support recovery and scale-out.