Collecting too much log data makes the “needle in the haystack” all the more difficult to find, but for practical reasons it is often easier to collect as much data as possible anyway and “sort it out later” via Seq retention policies.
These have served us well since the early versions of Seq, and selective retention is a feature that’s been widely appreciated by users. Retention policies do come at a cost however – as events are removed from the stream, space in the storage engine needs to be compacted and this can use significant resources on the server (CPU, RAM and I/O).
In many cases, it is preferable to drop uninteresting events as they arrive. This facility is now available in Seq 1.4.2-pre as “input filters”.
Each Seq API key can now specify a filter expression – just like the event stream supports – that identifies events that will be accepted when logged with the key:
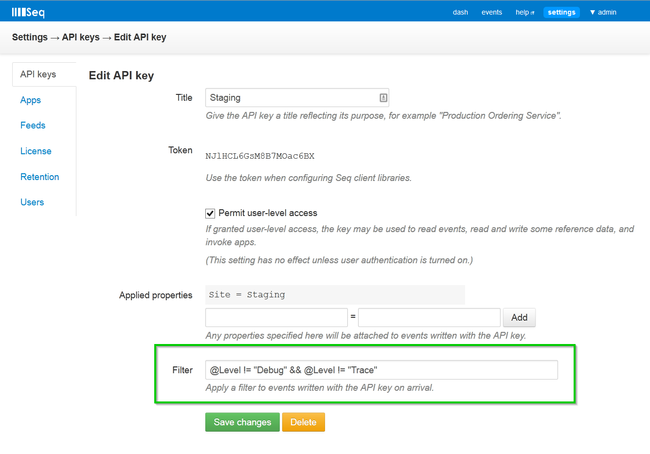
A typical use case may be to drop events below a certain level, but any criterion can be included.
If for any reason it becomes necessary to change the filter during operation, updating it takes immediate effect so that more or fewer events can be recorded.
It’s a simple feature right now that we’re looking for feedback on – if you can grab the new preview from the download page (preview link is at the bottom) and try it out it would be great to hear your thoughts!
Not currently in the preview, but also coming in 1.4 is a MinLevel() query function that will tidy up filtering by level like the example shows.