TL;DR: Dashboards, alerts and queries that include percentile calculations will run faster and more efficiently with Seq 2025.1, in exchange for a small reduction in accuracy.
A percentile, or quantile, is the value below which a fraction of values occur. For example, if all Australian adult woman were ordered by height, 75% would be shorter than 166 cm (5' 5.35"). Hence the 75th percentile is 166 cm.

Timing percentiles are a useful and popular summary of application performance. The following chart shows a histogram of @Elapsed time values from a real system.
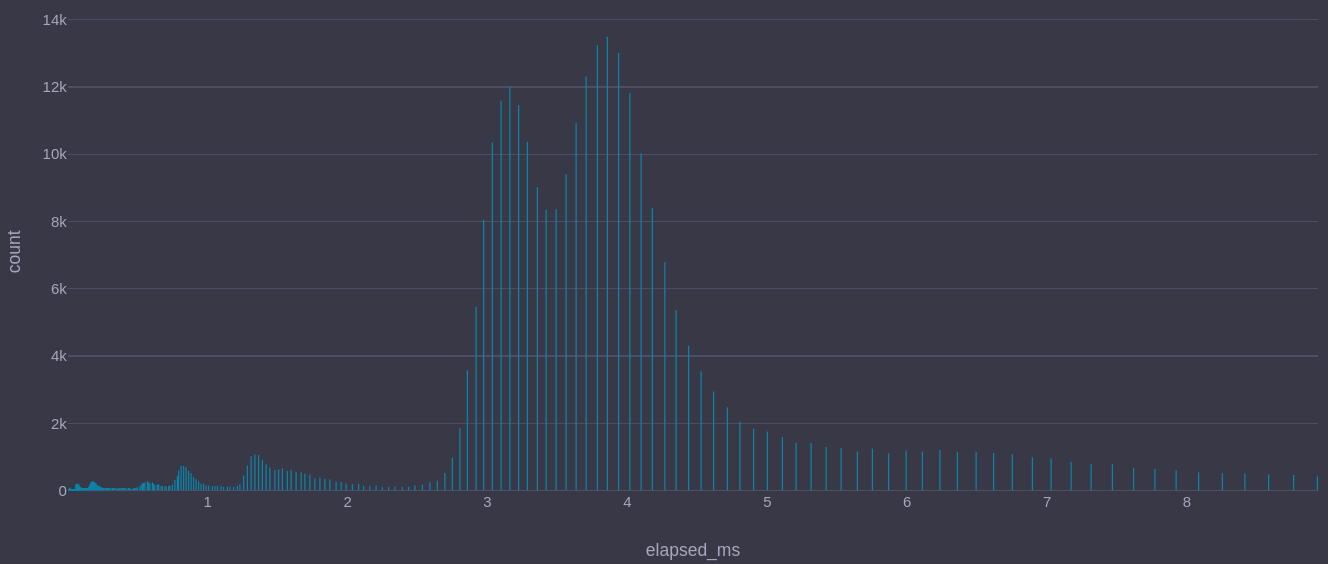
The distribution has seven distinct peaks. Summarizing these data as a median or mean statistic would be misleading because very different distributions can have the same median and mean. Percentile provides a meaningful measure of outlying values.
Calculating the percentile answers questions like, "what is the common worst-case latency?", where 'common' is defined by the choice of percentile.
To find the elapsed time that the system is faster than 90% of the time, we can query Seq for the 90th percentile:
select TotalMilliseconds(percentile(@Elapsed, 90)) as elapsed_ms from stream
For this dataset the 90th percentile is 6.23ms.
Seq has had a percentile function for a long time. It is commonly used for dashboard visualizations and alerts. Unfortunately, there is no parallel algorithm for percentile calculation, making percentile one of Seq's slowest operations. Furthermore, exact percentiles are hard to incrementally cache/memoize without using large amounts of memory.
Making percentile faster
Seq 2025 replaces the exact percentile calculation with a faster, and more memory efficient, approximate calculation. By allowing a small amount of error it becomes possible to parallelize the algorithm and take advantage of modern, multi-core processors. It is even possible to distribute a percentile calculation across nodes in a Seq cluster.
The signature of percentile now has a third, optional parameter:
percentile(<expression>, <percentile>, [<error_fraction> = 0.01])
The error fraction parameter specifies the largest acceptable error as a fraction of the value. For example, if the result of the percentile function is 100 and the error argument is the default 1% (0.01) then the true value must be between 99 and 101.
The smaller the error_fraction argument the more time and space is required for the percentile calculation. The following chart compares the speed of the percentile function between Seq 2024.3 and Seq 2025.1, by calculating the median @Elapsed value over a 20 GB sample dataset, on a modest desktop computer:
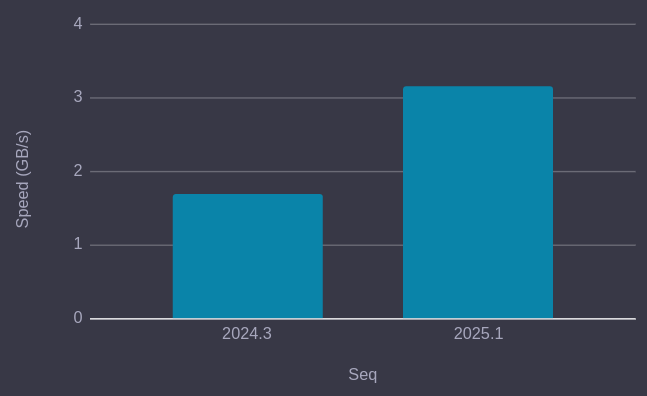
For this typical percentile calculation Seq is now twice as fast as the previous version.
What do I need to do?
Nothing! Percentile queries will automatically use the new, more efficient algorithm. If you would like faster queries with less accuracy, try increasing the error fraction. Conversely, use a lower error if you can accept slower queries for greater accuracy.
Seq 2025.1 is ready to try now: grab the binaries from https://datalust.co/download (look for the "preview" link) or pull datalust/seq:preview from Docker Hub.